

Over the last quarter, we’ve shipped major upgrades to Chalk that make it easier for ML and data teams to ship features faster, iterate confidently, and power production models with real-time data at scale. We expanded support for Python acceleration, improved system observability, and gave teams more control over how features are persisted, joined, and queried.
Write Python, Execute in C++
We expanded our Symbolic Python Interpreter to support more resolver types, enabling Chalk to compile more Python logic directly into C++ implemented Velox expressions. This gives you the ergonomics of Python with the performance characteristics of native execution.
For teams deploying high-throughput or latency-sensitive models, this means:
- Lower latency (sub-10ms) through native execution paths for more resolvers
- Higher scalability through vectorized operations (SIMD & no GIL)
- Faster development cycles with streamlined feature engineering (Python syntax—no DSLs)
Learn how our engineering team built this, and watch Nathan present it at Veloxcon '25.
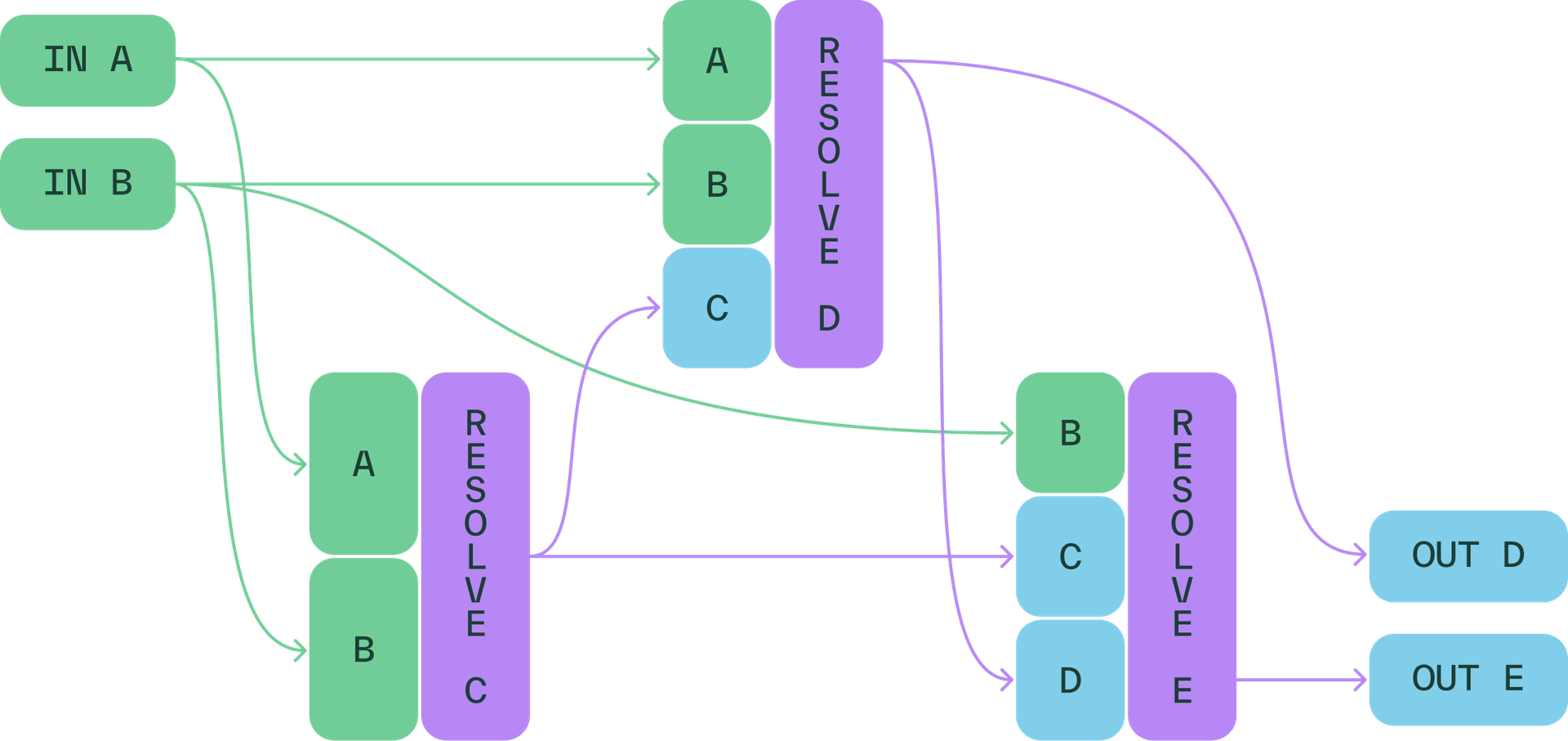
Greater control over how data is modeled, persisted, and reused
We introduced new patterns that give teams finer-grained control over how features are defined and managed in production:
- Selective feature persistence: Exclude intermediate or expensive fields (like raw text or embeddings) from online and offline stores with
store_online=Falseandstore_offline=False. - New aggregations: Functions like
array_median,max_by_n, andarray_sumunlock new statistical modeling patterns out of the box. - Expressive filtering & joins: Use Chalk Expressions for
.where()filters across DataFrames and has-many relationships. Support for composite key joins makes entity resolution in complex datasets much easier.
@features
class User:
id: str = _.alias + "-" + _.org + _.domain
org_domain: str = _.org + _.domain
org: str
domain: str
alias: str
# join with composite key
posts: DataFrame[Posts] = has_many(lambda: User.id == Post.email)
# multi-feature join
org_profile: Profile = has_one(lambda: (User.alias == Profile.email) & (User.org == Profile.org))
@features
class Workspace:
id: str
# join with child-class's composite key
users: DataFrame[Users] = has_many(lambda: Workspace.id == User.org_domain)Composite keys enable teams to model complex relationships that require multiple attributes for unique identification. This supports more accurate data modeling, flexible cross-dimensional joins, and proper data isolation in multi-tenant environments.
New observability tools for real-time systems
We made Chalk’s dashboard a more powerful tool for understanding system behavior, debugging edge cases, and optimizing for scale.
- The Online Query Performance tab surfaces SQL queries, resolver inputs/outputs, and acceleration insights—giving full visibility into how queries are executed in production.
- The Query Plan Viewer now highlights accelerated Python resolvers as yellow and displays the resulting static expressions they’ve been converted into.
- Feature-level observability includes most-used values, value counts, and slice-based metrics for each deployment—helping teams debug drift and detect regressions quickly.
- A new graph view for feature lineage makes it easier to understand how features are constructed, reused, and deployed across your system.
These improvements are especially valuable for teams operating in real-time domains like fraud, credit, personalization, and infrastructure optimization—where explainability and performance tuning are critical.
Customer spotlight: Apartment List and Verisoul
Teams are putting these upgrades to work already:
Apartment List rebuilt their recommendation engine with Chalk, delivering personalized results in real time by dynamically flexing price and location preferences and making low-latency API calls during inference. They went from nightly batch to always-fresh results—without refactoring their model. Read their story here.
Verisoul uses Chalk to iterate on fraud detection logic with minimal friction. They ship new features in hours (not weeks), improving precision and recall while reducing operational overhead. Read their story here.
Other highlights
- Improved Glue Catalog performance: Distribute training datasets to downstream teams (analytics, data science, etc.) by writing offline queries to Iceberg and your catalogs.
- Autoscaling with KEDA: Dynamically scale workloads based on event traffic (e.g. Kafka), now live across all customer clusters
- Vertex AI embeddings support: Use GCP’s Vertex models with Chalk’s built-in
embed()function.
class AnalyzedReceiptStruct(BaseModel):
expense_category: ExpenseCategoryEnum
business_expense: bool
loyalty_program: str
return_policy: int
@features
class Transaction:
merchant_id: Merchant.id
merchant: Merchant
receipt: Receipt
llm: P.PromptResponse = P.completion(
model="gpt-4o-mini-2024-07-18",
messages=[P.message(
role="user",
content=F.jinja(
"""Analyze the following receipt:
Line items: {{Transaction.receipt.line_items}}
Merchant: {{Transaction.merchant.name}} {{Transaction.merchant.description}}"""
))],
output_structure=AnalyzedReceiptStruct,
)
vector: Vector = embed(
input=lambda: Transaction.receipt.description,
provider="vertexai", # openai
model="text-embedding-005", # text-embedding-3-small
)We're continuing to invest in performance, observability, and developer experience—so teams can go from idea to production without slowing down. If you're building real-time ML and want to move faster, we'd love to show you what Chalk can do.





