

It's back-to-school season and we're back with another roundup of what the Chalk team worked on for the past few months! As always, you can follow along for weekly updates at our changelog.
Updated UI for features and resolvers
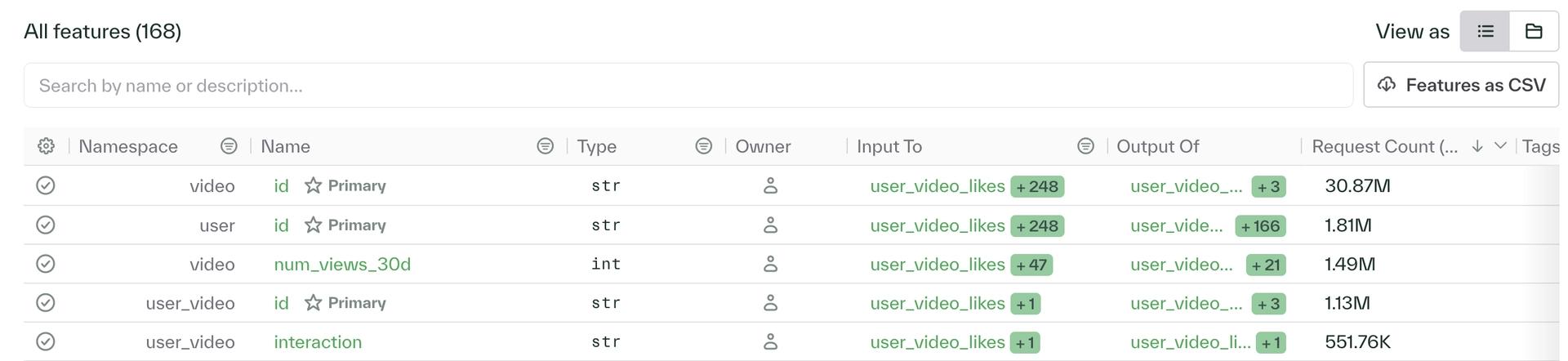
The Features and Resolvers sections of the Chalk dashboard have new functionality allowing you to filter, sort, and resize columns!

Additionally, the Features section shows the most recent request counts for each feature and has a button for downloading the table as a CSV report.
Queries can reference multiple feature classes
Previously, you could only reference one feature class in each query, which meant executing several queries to collect all of your features and then stitching the corresponding data back together. Now, you can request features from multiple feature namespaces in a single query!
For example, here’s a query where we retrieve information about a specific user and how they interacted with a video:
client.query(
input={
User.id: "12345",
Video.id: "98765",
UserVideo.id: "12345_98765",
},
output=[User, Video, UserVideo],
)Named queries
You can now define named queries, which allow you to document key use cases in code and execute queries just by referencing their name. Here's an example where we define a NamedQuery similar to the previous example with users and videos:
from chalk import NamedQuery
from src.feature_sets import User, Video, UserVideo
NamedQuery(
name="user_video_likes",
input=[
User.id,
Video.id,
],
output=[
User.id,
Video.id,
Video.num_views_30d,
UserVideo.id,
UserVideo.watch_duration,
UserVideo.interaction,
],
tags=["team:analytics"],
owner="analytics@example.com",
)After defining this query and running chalk apply, you can execute the query by name without enumerating all of the outputs:
chalk query --in user.id=123 --in video.id=456 --user_video.id=123_456 --query-name user_video_likesAs shown in the section above regarding our updated UI, named queries appear in the feature table in the "input to" and "output of" columns.
More functionality for expressions
Expressions have received several changes over the past few months! Expressions are a terse syntax for expressing simple transformations and aggregations of other features in the same feature class.
- You can now use
_.chalk_windowin windowed aggregations to reference the current target window. - You can now use the
chalk.functionsmodule with expressions for common feature transformations. You'll find functions for unzipping, hashing, coalescing, and converting data types.
Native support for PartiQL with DynamoDB
We now support using PartiQL with DynamoDB! PartiQL is a great tool for DynamoDB because its queries can be translated into fast, native DynamoDB queries.
As a bonus, our teammate Bill Qin wrote a deep dive on how he changed our PartiQL parser to support column aliasing for the sake of creating a better developer experience. It's always fun to see different use cases for manipulating ASTs in production!
New tutorial for using Chalk with AWS SageMaker
We have a new tutorial showing how you can use Chalk within a SageMaker pipeline for model training and evaluation. In short, Chalk is a great feature engineering platform because you can use the same code across your notebooks, training, and serving. Meanwhile, SageMaker shines for model training and serving. With their powers combined, you can build a streamlined model training and serving system that uses the best of both systems.
Updated documentation
- We updated our time documentation. Don't worry, the concept of time has not changed, but we hope our new docs are easier to digest.
- We also updated the documentation for expressions. We've also added an index of all available expressions.





