TRAINING DATA
Train models with
production features
Generate point-in-time correct training datasets from the same feature definitions you use in production and serve production features from your training data. Keep training and inference aligned and eliminate skew.

Trusted by the teams building next generation of AI + ML
Training-serving consistency
Evaluate training with the same feature definitions and resolvers used online to eliminate skew and rewrites.
High-throughput, large scale
Generate billions of rows of training datasets through distributed offline queries without provisioning infrastructure.
Point-in-time correctness
Evaluate features using only the data available at each historical moment to avoid leakage and ensure accurate training inputs.
Branch-based experimentation
Create feature branches, generate comparison datasets, and seamlessly promote winners to production.
Chalk is a key part of our underwriting pipeline, letting us test new code against production pipelines without disruption. We can quickly iterate on new features and enhancements, helping us offer more flexible capital products than anyone else.
Nate Wiger CTO
Generate point-in-time datasets
from production features
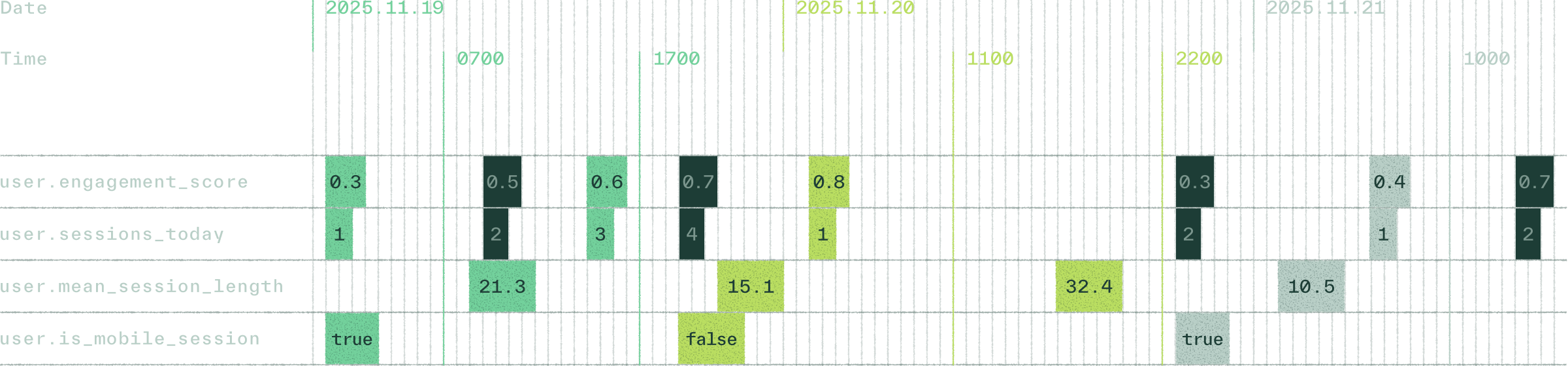
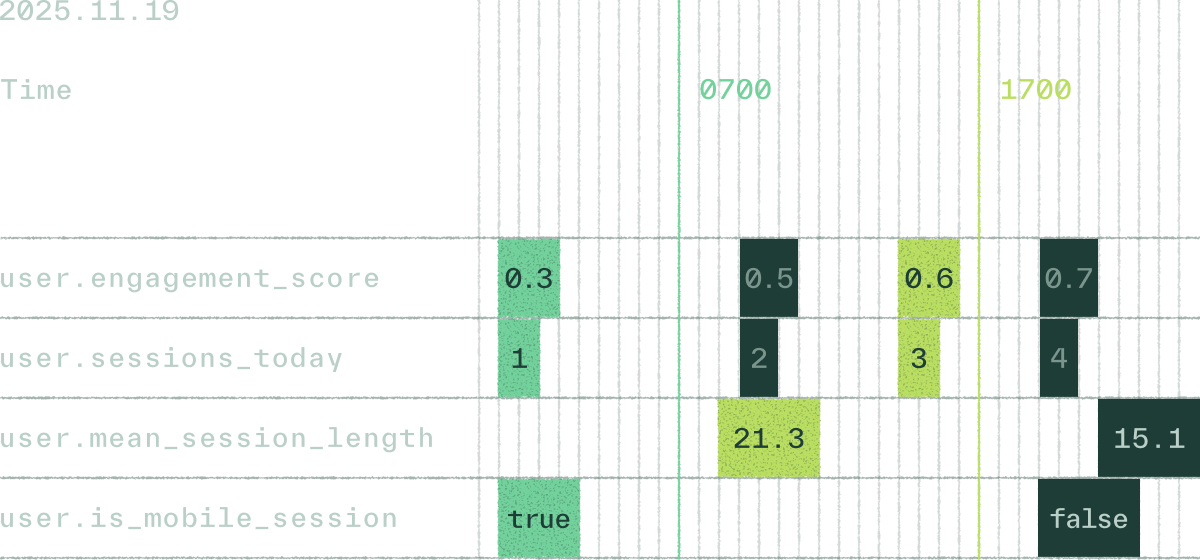
Point-in-time evaluation ensures features are computed using only the values available at each historical moment. This removes leakage, produces reproducible datasets, and allows offline experiments to reflect production behavior.
Explore offline queriesIntegrate with your model training workflow
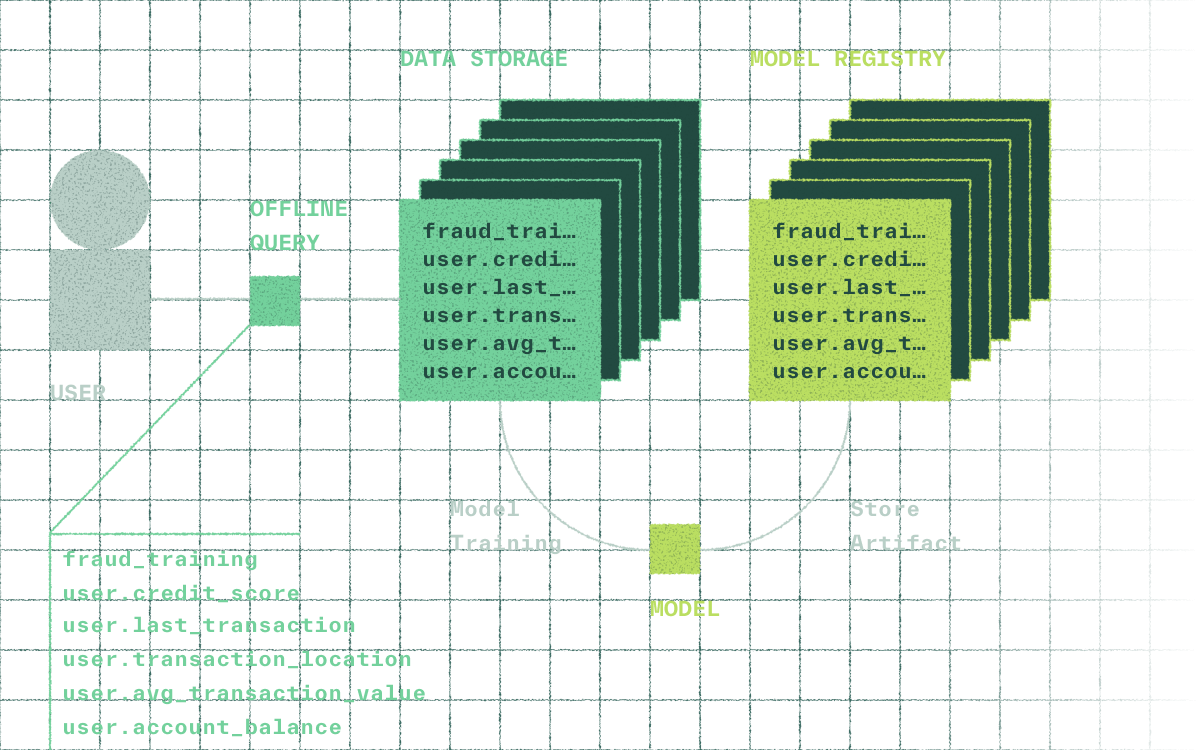
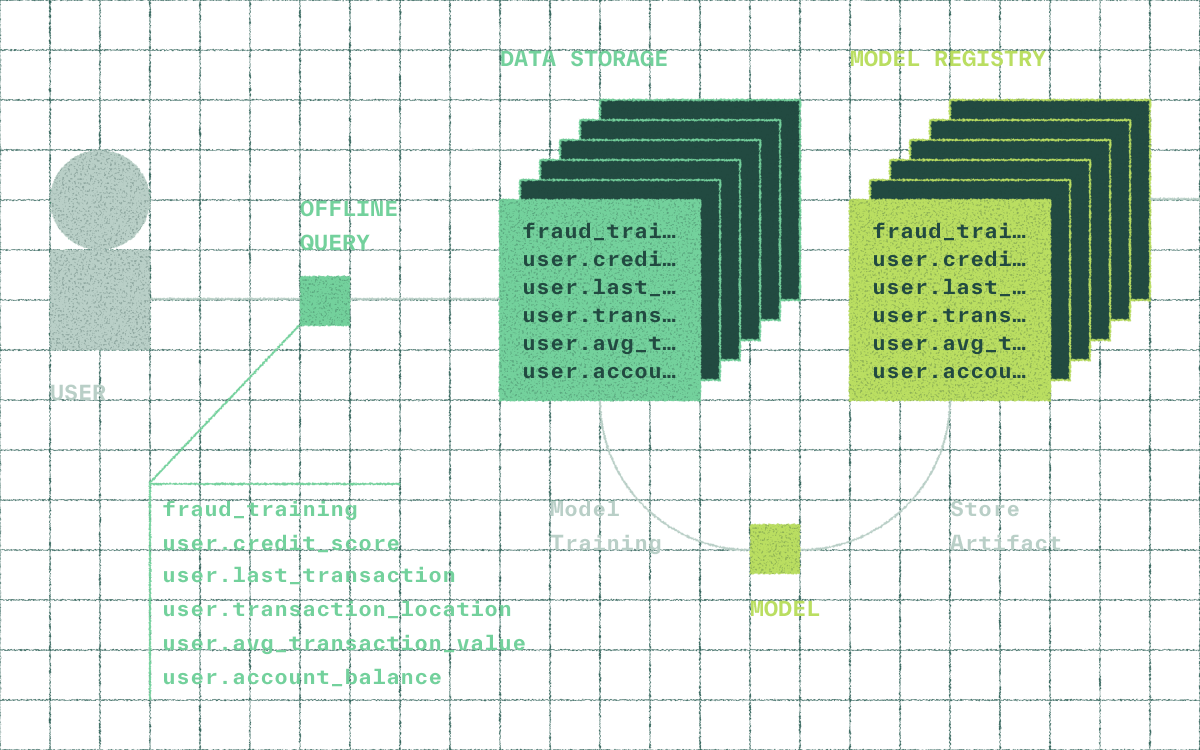
Integrate with your model training workflow
Training datasets generated with Chalk integrate directly into your model training workflow. Chalk preserves the schemas and evaluation semantics used in production so models train on the same feature logic they use at inference.
Model trainingBackfilling with chalk.now
Backfilling with chalk.now
Evaluate features as if it were any point in time. Train on historically accurate windows, then serve the same features in production with no drift or leakage.
Use chalk.nowThe latest at Chalk
Train your models
with production features
Talk to an engineer and see how Chalk can power your production AI and ML systems.