UNDERWRITING
Underwriting demands
real-time data
Underwriting decisions depend on fresh, high-conviction data. Chalk is the federated query execution engine behind modern credit and underwriting teams. It computes features at decision time, enables faster iteration, and scores applications in single-digit milliseconds at scale.
TALK TO AN ENGINEER
Trusted by credit leaders
Why Chalk for underwriting models
Ship new credit signals fast
Compute features like FICO blends, inquiry velocity, delinquency counts, and balance trends using decision-time data instead of batch aggregates
Unify credit data
Compute credit features across bureau, banking, and application data including cash-flow and account-level signals from providers like Plaid
Deploy consistently
Use the same feature definitions for training, backtesting, and live scoring
Ship new credit signals fast
Compute features like FICO blends, inquiry velocity, delinquency counts, and balance trends using decision-time data instead of batch aggregates
Unify credit data
Compute credit features across bureau, banking, and application data including cash-flow and account-level signals from providers like Plaid
Deploy consistently
Use the same feature definitions for training, backtesting, and live scoring
Improve approval accuracy
Decision with live credit bureau, banking, and and third-party signals instead of stale aggregates
Reduce portfolio risk before approval
Detect recent delinquencies, inquiries, cash-flow changes, and balance changes in real-time
Meet compliance requirements
Operate with built-in lineage, audit logs, and versioned feature definitions
Credit decisions at scale

Credit decisions at scale
Mission Lane leverages Chalk to unify offline and online features, cut deployment time from weeks to days, and move to real-time credit decisions.
READ STORYMake instant credit decisions
with alternative data
Compute underwriting features using banking, cash-flow, and identity signals at decision time, enabling approvals that do not rely solely on traditional credit scores.
Assess short-term credit risk
using real-time financial behavior.
Evaluate recent income, account balances, and spending patterns using decision-time features, which is critical for cash advance products where FICO alone is insufficient.
Underwrite businesses using
a live view of financial health.
Compute features from bank accounts, revenue forecasting from Stripe, and Quickbook expense data to assess risk and approve loans for businesses.
Approve access and set limits
at the moment of issuance.
Combine bureau data with recent banking and transactional signals to determine eligibility and limits for new card products at decision time.
Compliant credit decisions
Version every feature, audit every change, and trace data lineage automatically. Chalk ensures every underwriting decision is transparent and regulator-ready.
Lineage DocsReal-time credit signals

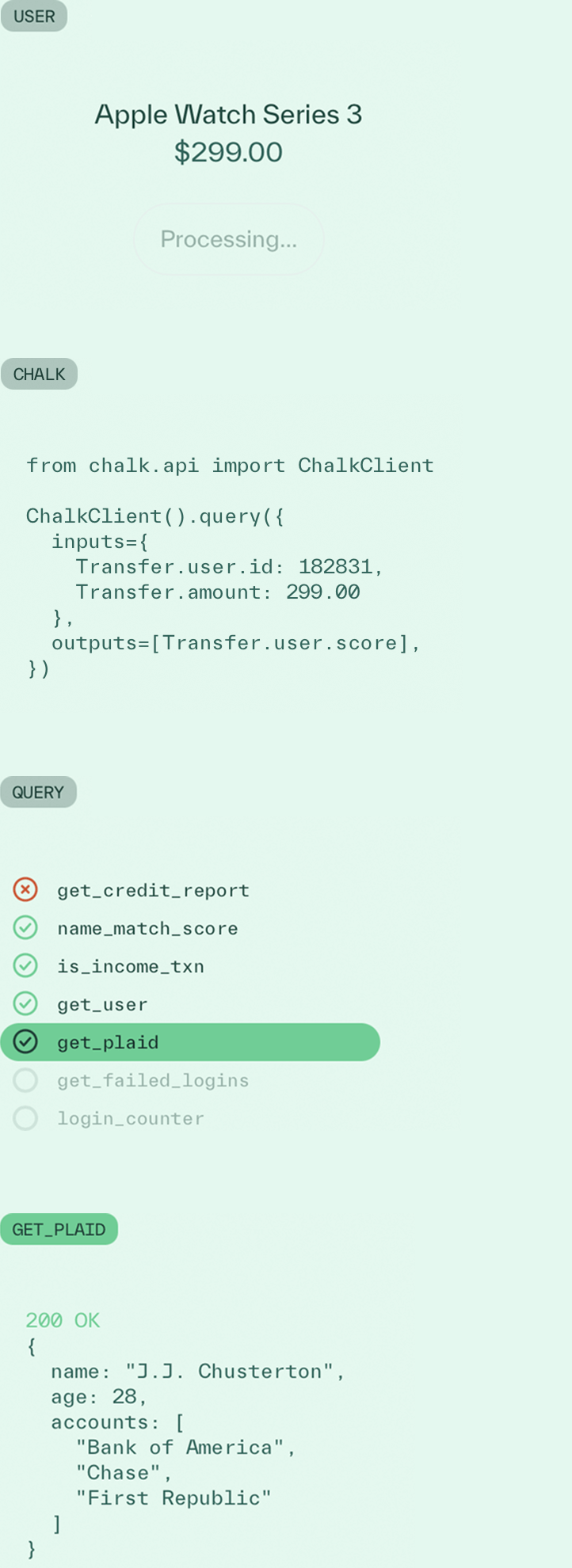
Fetch bureau data, banking signals from providers like Plaid, and alternative sources at decision time. Combine streaming and historical data to support accurate approvals in emerging credit products where traditional bureau data falls short.
Every feature has to be precise. A single misaligned timestamp can change a lending decision. Chalk’s feature engine gives us conviction that every feature value is right.
Robert Theed Backend Tech Lead, iwoca
More resources
Ready to level up your
underwriting models
Get started with Chalk today and build fraud detection infrastructure that moves at the speed of your business.
TALK TO AN ENGINEER


