

PartiQL is a SQL dialect that can be translated into fast, native DynamoDB queries. We wanted to offer a way for our DynamoDB users to run PartiQL queries against their DynamoDB data sources, but there was one small wrinkle: DynamoDB's PartiQL dialect is too limited for use in Chalk SQL.
In this blog post, we’ll discuss how we worked around these limitations to provide full support for customers using DynamoDB data sources with Chalk. We’ll dive into the details of how Chalk uses abstract syntax trees (ASTs) to parse and transform SQL.
Background
Chalk is a machine learning platform that lets you define your features (also known as signals or dimensions) in idiomatic Python. Feature extraction pipelines are automatically built from “resolvers”, which describe how to compute these features.
Here's an example where we define features representing facts about our users and retrieve raw feature data from DynamoDB:
from chalk.features import features
@features
class User:
id: str
name: str
age: intWith Chalk, you can define SQL file resolvers, which populate features from your database. This SQL file resolver queries a DynamoDB instance to retrieve these values:
-- type: online
-- resolves: user
-- source: our_dynamodb
SELECT
id, name, age
FROM
users;Chalk builds an internal graph of your features and resolvers, so it understands that queries for User.id, User.name, and User.age should invoke this SQL query.
Importantly, Chalk implicitly maps the names of these columns to the names of features. If your database's column names are not an exact match for your Chalk feature names, we generally advise you to alias them using AS:
-- type: online
-- resolves: user
-- source: our_dynamodb
SELECT
id, full_name AS name, age
FROM
users;And here's our wrinkle: PartiQL does not support AS in SELECT clauses!
We considered several options:
- Tell our users to rename their features to match their DynamoDB column names.
- Problem: We cannot ask customers to rename columns and modify existing infrastructure just to use Chalk.
- Add a way to define the name mapping within the file's metadata comments, such as with
-- rename: foo bar.- Problem: Metadata comments are fine for Chalk-specific concepts, but they felt too magical in this situation.
- Add a way to set an alias for the feature within Python code (e.g.,
name: str = field(resolver_alias="full_name")).- Problem: Putting the alias in the feature definition means that the SQL file resolver is not an independent source of truth about the feature mapping, which is confusing.
- Find a way to allow
ASwithin PartiQL resolvers- 🏆 This solution is intuitive and maintains consistency with other SQL data sources. This will require additional work under the hood, but is the best experience for our users.
Although it was the most complex option, we decided the last option would be the most consistent and intuitive user experience. Our goal was to parse PartiQL queries and directly edit the abstract syntax trees (ASTs), and ultimately come up with a flavor of PartiQL that allows AS aliasing.
Here's an overview of the steps we took:
- Parse PartiQL queries to retrieve a mapping from column names to aliases
- Run the query as valid PartiQL against DynamoDB
- Apply the aliases to the query results
Parse PartiQL queries
First, we need to parse queries so that we can find the AS alias parts.
An initial candidate for this type of work was SQLGlot, which is capable of creating the AST, modifying it, and transpiling it into any dialect we want. However, SQLGlot requires the bulk of work to occur in Python, where we would be subject to GIL-bound computation, which dramatically reduces performance.
We instead chose to use DuckDB's SQL parser, which gave us access to an AST in C++. On the flipside, we have to do the work to transpile the AST back into a SQL string. We decided this tradeoff was worthwhile for improved performance.
Here's how we run DuckDB’s parser on PartiQL queries to get an AST:
duckdb::Parser p;
try {
p.ParseQuery(sql);
} catch (const duckdb::ParserException &e) {
...
}ASTs are a data structure that represent the structure of code. They're a fundamental building block for writing compilers and executing code for programming languages. They make it easier for us to programmatically retrieve the properties we care about without writing impossible regular expressions.
For example, for the following SQL query:
SELECT
id,
full_name AS "name",
FROM
users
WHERE
status="active";We would generate this AST:
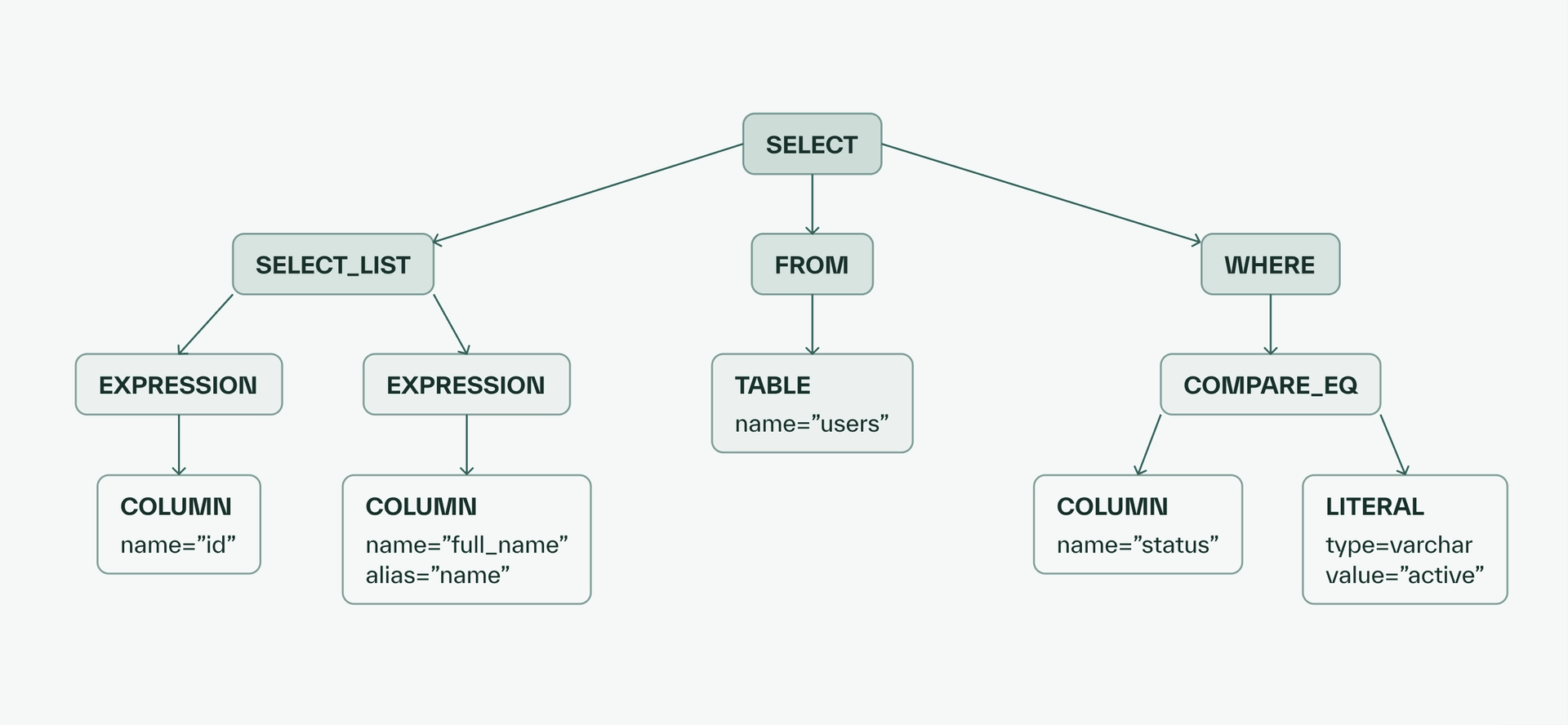
Starting from the root SELECT node, its child nodes include nodes for the SELECT clause, FROM clause, and WHERE clause. Within SELECT_LIST, there are nodes representing the id column as well as the full_name column. The full_name column node contains the alias property we care about.
Here’s an abridged look into the COLUMN object in the DuckDB AST:
namespace duckdb {
class BaseExpression {
public:
string alias;
virtual string ToString() const = 0;
...
}
class ParsedExpression : public BaseExpression {...}
class ColumnRefExpression : public ParsedExpression {
public:
string column_name;
...
}
}
We iterate over the SELECT_LIST node and retrieve the aliases. For aliased column references, we store the mapping of the column name to the alias. Finally, we remove the alias from the AST. In our example, we traverse the AST and store the mapping from the full_name column to its intended alias, name, and remove the alias value from ColumnRefExpression.
Run the query
Now that we have stored the column mapping and edited our AST to remove the aliases, we’re ready to convert our AST back into a SQL string. Unlike the previously-mentioned SQLGlot, the DuckDB AST was not created with the intention of converting back into SQL; it was created to query DuckDB. Because of this, just calling the built-in ToString() method, which converts queries into one specific dialect of SQL, does not always work. Different dialects have different semantics. Examples of differences include:
- Different types of brackets for array literals:
(1,2,3)vs[1,2,3] - Different quotes for column identifiers:
"foo"vs`foo` - Different reserved keywords
To get around this, we created a custom method that takes a SQL dialect and a DuckDB AST and returns the correct SQL string. Here’s a peek into what that looks like:
namespace chalk_internal::sql {
template <SQLDialect Dialect>
std::string DialectWriter<Dialect>::query_select_node_to_string(const duckdb::SelectNode &expr) {
std::stringstream result;
// CTEs
...
// SELECT
result << "SELECT ";
...
for (size_t i = 0; i < node.select_list.size(); i++) {
if (i > 0) {
result << ", ";
}
auto select_expr_as_str = expression_to_string(*node.select_list[i]);
result << select_expr_as_str;
if (!node.select_list[i]->alias.empty()) {
result << " AS ";
result << write_with_quotes(node.select_list[i]->alias, DialectInfo<Dialect>::identifier_quote);
}
}
// FROM, WHERE, GROUP BY, HAVING, QUALIFY, etc.
...
return result.str();
}
}Using this, we're able to produce a valid PartiQL query:
SELECT
id,
full_name
FROM
users
WHERE
status="active";Add the aliases to the results
Finally, we send our modified query to DynamoDB and parse the results. We rename the columns, and we’re done!
outcome = client->ExecuteStatement(request);
if (!outcome.IsSuccess()) {
// Error handling
}
const auto &result = outcome.GetResult();
// Populate our record batch builder with the result
std::shared_ptr<arrow::RecordBatchBuilder> result_builder = create_result_builder(result);
auto result_record_batch = result_builder->Flush().ValueOrDie();
// Rename the columns!
auto renamed_results = result_record_batch->RenameColumns(mapping_info).ValueOrDie();
return renamed_results;Conclusion
Being able to query a variety of different data sources is critical to Chalk’s mission of delivering a bleeding-edge feature engineering experience. Supporting and extending PartiQL to query DynamoDB allows customers with large AWS ecosystems to access their data with very little overhead, without compromising on developer experience.
If building low latency products with great developer experience sounds exciting to you, check out our open roles at chalk.ai/careers.





