

As the year comes to a close, the Chalk team has been hard at work delivering powerful new features to enhance your workflows, improve observability, and streamline integrations. This release is packed with updates designed to help you unlock new efficiencies, achieve better performance, and close out the year on a high note. As always, you can stay updated with our weekly changelog.
More functionality for expressions
Chalk expressions have been significantly expanded to simplify feature engineering workflows and boost performance through static analysis and C++ compilation. You can now reference fields within structs, and the expanded chalk.functions library enables creating logical expressions, transforming features, and integrating predictions directly into workflows by running SageMaker predictions with F.sagemaker_predict. Check out the full library of chalk.functions to unlock new transformations with less code and more speed.
Dashboard improvements featuring more metrics and observability
Several updates have been made to the dashboard to enhance observability across your features, resolvers, queries, and cluster details. The revamped overview page now provides comprehensive metrics, including insights into recent online and offline queries, resolver runs, deployments, errors, and the status of all connections in your environment.
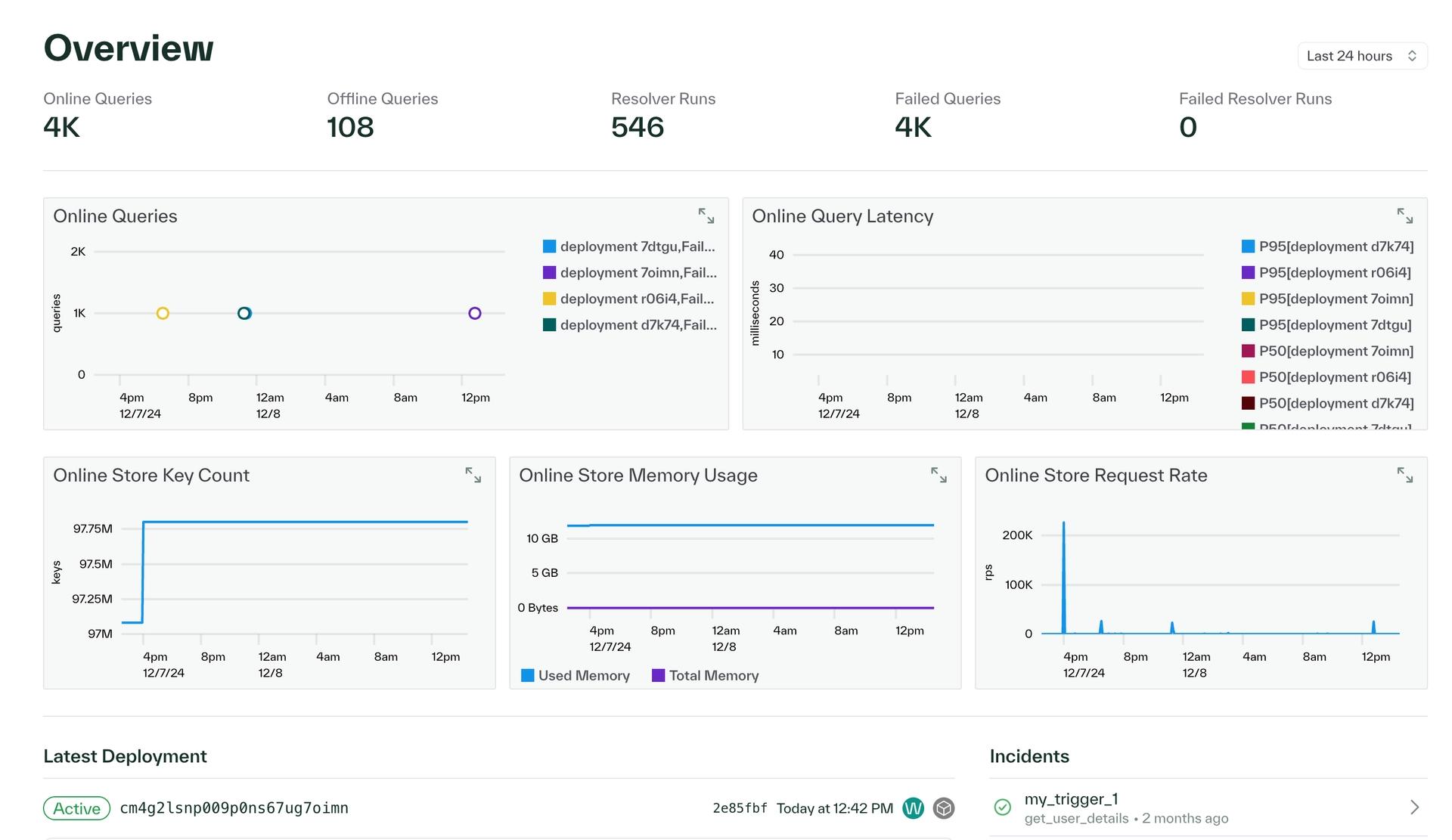
To enhance monitoring, we've added warning banners in the dashboard to alert you to issues in deployments, such as pods failing to start up cleanly. For deeper visibility, the deployments page now displays the kubernetes pod resources associated with each deployment. Additionally, for more granular observability, you can view the latest stack trace for each pod in your cluster and filter logs by pod name, resource group, deployments, and more.
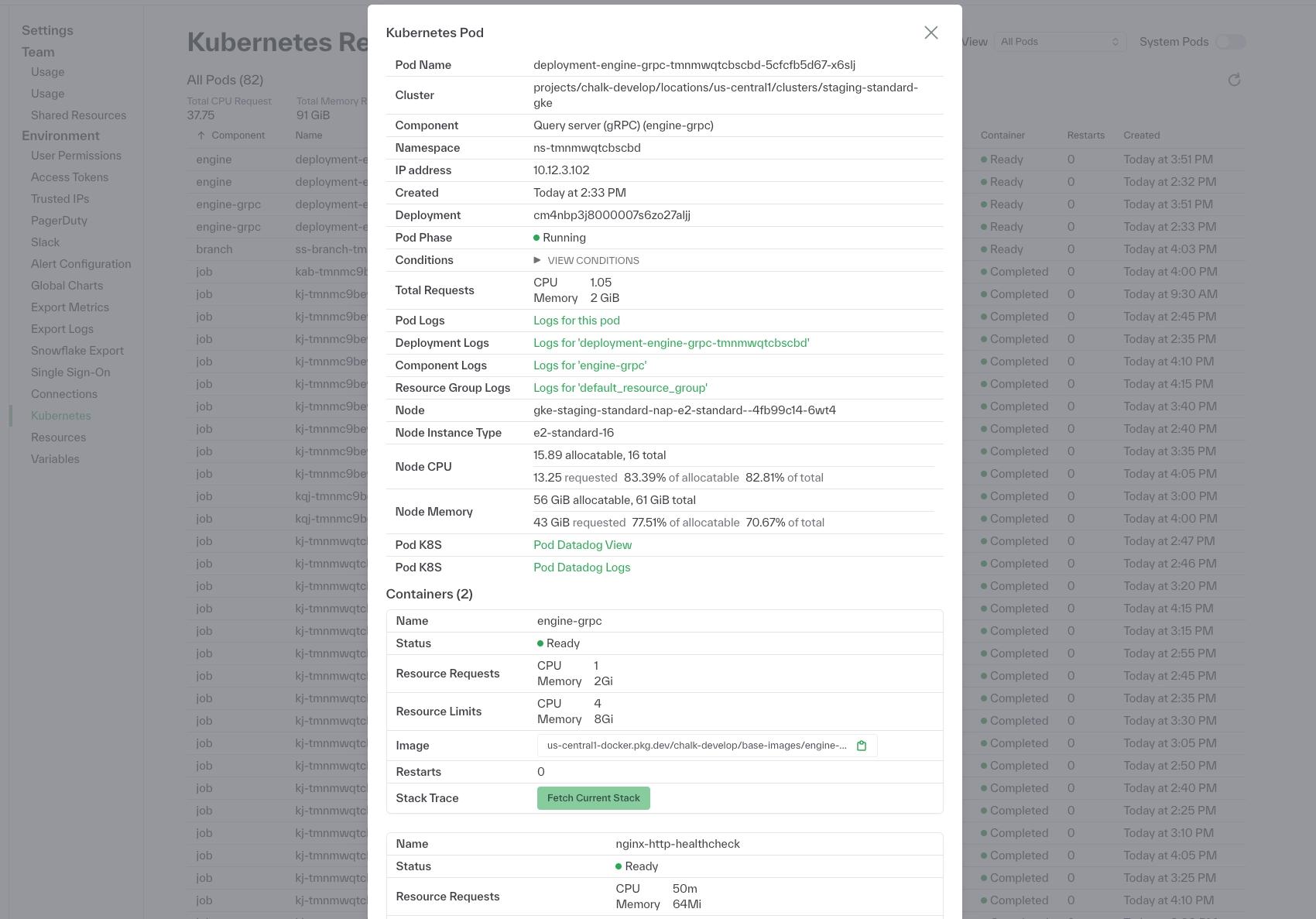
Enhanced filtering and exploration capabilities now make it easier to gain precise insights across the dashboard. In the resolver table, you can view p50, p75, p95, and p99 latency statistics, while customizing column selection for comparisons. The usage dashboard supports filtering and grouping by cluster, environment, namespace, and service. In environments with a gRPC server, the features page presents feature value metrics and recently computed feature values loaded from the offline store. Lastly, a SQL explorer has been added to the dashboard, allowing you to run SQL queries against datasets, including query outputs, for faster data exploration and analysis.
Offline query improvements
Offline queries are now more powerful and flexible with several key improvements. They can accept parquet files as input by passing in a s3:// or gs:// URL to the offline_query(input="...") parameter. You can also control the parallelization of offline query execution by specifying the num_shards and num_workers parameters. Additionally, upper and lower bounds for offline queries now support timedelta inputs, enabling dynamic time-based constraints, such as offline_query(upper_bound=timedelta(days=30) to set the upper bound to be 30 days after the latest input_time. Lastly, the store_online and store_offline parameters allow you to seamlessly store offline query outputs online and offline, respectively, for improved integration.
Optionally cache null or default feature values in online store
The @features decorator now includes cache_nulls and cache_defaults as parameters, which specify whether to cache and update null or default computed feature values in the online store. For DynamoDB or Redis online stores, these parameters also accept cache_nulls="evict_nulls" or cache_defaults="evict_defaults" to evict null or default feature values from the online store, prompting online resolvers to rerun and compute up-to-date results.
Integration testing with ChalkClient
The ChalkClient now supports integration testing for your features and resolvers through the .check() method. This method allows you to deploy local changes, query against branches in a codified way, and run integration tests in your CI/CD pipeline.
from chalk.client import ChalkClient
from chalk.features import DataFrame, features, FeatureTime, _
from chalk.streams import Windowed, windowed
import datetime as dt
import pytest
@pytest.fixture(scope="session")
def client():
return ChalkClient(branch=True) # Uses your current git branch
@features
class Transaction:
id: int
user_id: "User.id"
amount: float
ts: FeatureTime
@features
class User:
id: int
transactions: DataFrame[Transaction]
transaction_count: Windowed[int] = windowed(
"1d", "3d", "7d",
expression=_.transactions[_.ts > _.chalk_window].count(),
)
def test_transaction_aggregations(client):
now = dt.datetime.now()
result = client.check(
input={
User.id: 1,
User.transactions: DataFrame([
Transaction(id=1, amount=10, ts=now - dt.timedelta(days=1)),
Transaction(id=2, amount=20, ts=now - dt.timedelta(days=2)),
Transaction(id=6, amount=60, ts=now - dt.timedelta(days=6)),
])
},
assertions={
User.transaction_count["1d"]: 1,
User.transaction_count["3d"]: 2,
User.transaction_count["7d"]: 3,
}
)Miscellaneous features and improvements
- A new chalk usage command has been added to retrieve and export Chalk usage data.
- The chalk healthcheck command allows you to check the health of the Chalk API server and its services.
- Poetry is now supported for managing Python dependencies, providing a streamlined way to configure your Chalk environment. Read more about how to configure your Chalk environment here.
- Pub/Sub is now supported as a streaming source. Read more about how to configure your Pub/Sub source here.
- An idempotency key is now available to ensure that only one job is triggered per idempotency key, preventing duplicate executions.





