Chalk for AI + ML Engineers
Experiment faster, unify structured and unstructured data, serve features in real time, and power models with production-grade infrastructure, all from a single Python interface.
Talk to an Engineer

Trusted by teams building the next generation of AI + ML
Why AI/ML engineers choose Chalk
Unified data for every modality
Work with structured data like transactions and aggregations, and unstructured inputs like text, embeddings, and prompts
Faster experimentation loop
Experiment faster by defining features once in Python and reusing them across training and inference
Reliable, point-in-time datasets
Generate reliable training data with point-in-time correct backfills
Low-latency model serving
Serve models in real time with sub 5ms feature retrieval from heterogeneous sources
Chalk powers our LLM pipeline by turning complex inputs like HTML, URLs, and screenshots into structured, auditable features. We can serve lightweight heuristics up front and rich LLM reasoning deeper in the stack, catching threats others miss without compromising speed or precision.
Rahul Madduluri CTO
LLM-ready infrastructure
LLM-ready infrastructure
LLM toolchain extends feature engineering into the world of GenAI
- Embeddings support: define, store, and retrieve embeddings as features
- Prompt construction: build structured, dynamic prompts using Chalk features
- Vector search: retrieve semantically relevant context at query time
With Chalk, AI/ML engineers can combine structured and unstructured data for more accurate, context-rich LLM applications.
EXPLORE LLM TOOLCHAINBuilt for performance + scale
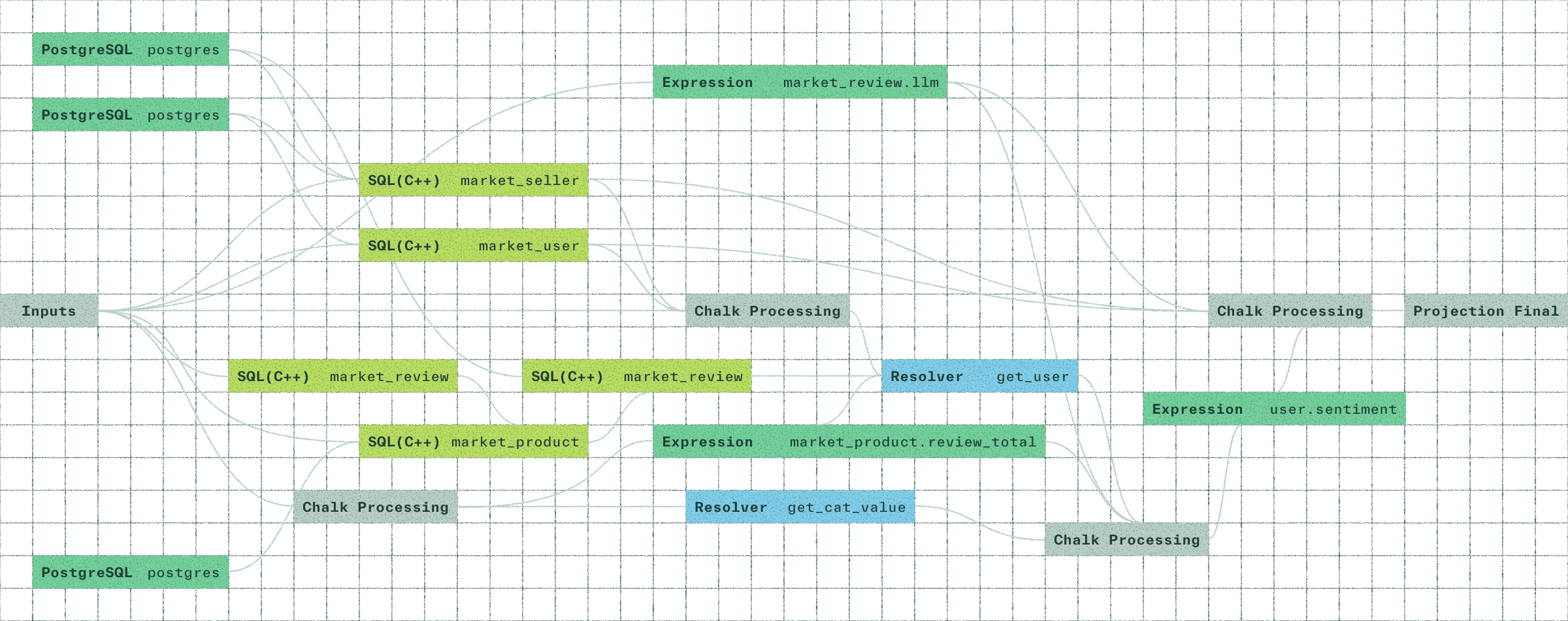

Chalk’s compute engine, powered by Velox, delivers vectorized, low-latency execution across both batch and real time. Features are served in less than 5ms, even with complex transformations and joins.
REAL-TIME SERVINGFrom training to
real‑time inference
From training to
real‑time inference
Chalk unifies structured and unstructured data from the start of model development. This single definition can be:
- Backfilled into training datasets
- Served in real time at inference with millisecond latency
- Versioned and reproduced at any point in time
Chalk ensures models are trained and deployed on the same feature logic, eliminating drift.
Explore how Chalk works
Ready to ship next‑gen AI/ML?
Talk to an engineer and see how Chalk helps AI/ML engineers deliver faster experimentation, real‑time inference, and LLM‑powered applications.