

Large Language Models have revolutionized how engineering teams explore, interact with, and leverage their data. With just a single prompt, LLMs can operate as a variety of specialized models—from analyzing unstructured data and automating routine workflows to orchestrating complex agentic systems. Currently, LLM workflows usually involve shuffling data between multiple tools and services. Teams still struggle to confidently evaluate and deploy LLM-powered systems into production.
Chalk is changing that. In this post, we’ll show how teams can use Chalk to accelerate prompt development and evaluation—by running them alongside feature engineering and model inference in a single unified platform.
And to demonstrate these capabilities, we answer the burning question: “Which model would win at Christopher Nolan trivia?”
Background
Chalk is a comprehensive data platform for real-time inference at scale. Our goal is to help machine learning teams move quickly from ideation to deployment for any complex workload. With just a few lines of code, engineers can incorporate new data sources, compute new features via Python functions, and deploy their models.
This same workflow extends to LLMs, making them first-class citizens in your ML stack. To support LLM workloads, Chalk provides a unified interface for inference, reducing boilerplate and increasing reliability. With prompt evaluation, developers can now test, trace, and deploy prompts directly alongside traditional ML pipelines.
This makes it easier to launch evaluations across prompts, models, parameters, and criteria using your own historical or curated datasets—without switching contexts or tools.
Creating a benchmark dataset
For this walkthrough, our problem statement is: which LLM performs best at Christopher Nolan trivia?
We’re using this example not just for fun—but to showcase a repeatable workflow: how to define an evaluation dataset, run prompt tests at scale, and promote the best-performing configuration to production.
We define a trivia set using questions sourced from Wikipedia and IMDb’s Nolan trivia pages. To scope the task and reduce ambiguity, we use a multiple-choice format. While this introduces the risk of lucky (hallucinated) guesses, it offers an entry point for evaluating model performance.
Here’s a sample trivia question that exhibits information retrieval and some reasoning:
Which of the following themes has NOT been explored in a Christopher Nolan film?
A. The nature of time
B. Personal identity
C. Religious salvation ← (Correct Answer)
All 50 questions used for this evaluation can be found here.
To upload this dataset to Chalk, we first define our data model. We’ll have 3 columns: nolan_trivia.id, nolan_trivia.question, and nolan_trivia.actual_answer that will be read directly from a dataset. In python, this will look like:
from chalk.features import features
@features
class NolanTrivia:
id: int
question: str
actual_answer: strThen, we can create the dataset by sending the CSV data to Chalk.
from chalk.client import ChalkClient
import pandas as pd
nolan_trivia_df = pd.read_csv("/path/to/nolan-trivia.csv")
chalk_client = ChalkClient(
client_id="<CLIENT_ID>",
client_secret="<CLIENT_SECRET>",
)
chalk_client.create_dataset(
input=nolan_trivia_df,
dataset_name="nolan_trivia",
)Defining a prompt
In Chalk, prompts are defined just like features—using strongly typed Python functions, composable logic, and declarative interfaces.
Here, we’re building a prompt to maximize accuracy on Nolan trivia. In Chalk, a “prompt” is a bundle of model choice, messages, and parameters. We define a system message to establish behavior, and dynamically populate the question using Jinja templating from our dataset.
This setup allows us to reason about input/output behavior in isolation—a hallmark of Chalk’s local-first UX over a real-time compute graph.
system_message = """You are a Christopher Nolan expert with comprehensive knowledge of his filmography, artistic techniques, personal history, and career achievements.
Your purpose is to accurately answer trivia questions about Nolan with precision and confidence.
When presented with questions, carefully analyze each option before selecting the most accurate answer.
If you're uncertain about any details, reason through what you know about Nolan's career, filmmaking style, and public statements to make an educated assessment.
Provide brief explanations for your answers when appropriate, citing relevant films, interviews, or known facts about Nolan.
You should be able to identify incorrect options by recognizing inconsistencies with established facts about Nolan's life and work."""
user_message = """Please answer the following Christopher Nolan trivia question.
Provide just the letter of the correct answer.
Do not provide any additional context or reasoning.
The only correct answers are A, B, or C.
Question: {{nolan_trivia.question}}
Answer: """Testing the prompt
Before scaling up, we need to validate that the prompt works correctly across different models and fine-tune parameters. Chalk makes this straightforward: we provide a unified interface allowing users to run completions and inspect detailed usage and runtime statistics directly in the notebook environment.
Every Chalk completion returns a structured PromptResponse object that saves important metadata around the response. This means we can access token counts, latency metrics, and retry information as simple class properties, making it easy to track costs and performance during development.
Let’s test our prompt on a single question in a notebook:
from chalk import _, functions as F, prompts as P
# Sample 1 question
sample_question = nolan_trivia_df.sample(1).iloc[0].to_dict()
# Define the completion feature
NolanTrivia.completion: P.PromptResponse = P.completion(
model="gpt-4o",
messages=[
P.message(role="system", content=system_message),
P.message(role="user", content=F.jinja(user_message)),
],
temperature=0.2,
max_tokens=1,
)
# Extract response information as attributes
NolanTrivia.response = _.completion.response
NolanTrivia.total_tokens = _.completion.usage.total_tokens
NolanTrivia.total_latency_s = _.completion.runtime_stats.total_latency
# Define an accuracy evaluator function
NolanTrivia.correct = _.response == _.actual_answer
chalk_client.query(
input=sample_question,
output=[
NolanTrivia.id,
NolanTrivia.question,
NolanTrivia.actual_answer,
NolanTrivia.response,
NolanTrivia.total_tokens,
NolanTrivia.total_latency_s,
NolanTrivia.correct,
],
)Running this test gives us a complete picture of how our prompt performs:
{
"nolan_trivia.id": 38,
"nolan_trivia.question": "Which of the following themes has NOT been explored in a Christopher Nolan film? A. The nature of time B. Personal identity C. Religious salvation",
"nolan_trivia.actual_answer": "C",
"nolan_trivia.response": "C",
"nolan_trivia.total_tokens": 217,
"nolan_trivia.total_latency_s": 0.5016413039998042,
"nolan_trivia.correct": true
}Great! The model correctly identified (C) as the correct answer.
Aside: While experimenting, you’ll often discover model-specific quirks. For example, we found that Gemini models add a trailing \n, which would break our exact-match evaluation. The fix here is simple: add a stop parameter. This is exactly why we test samples before scaling up.
Now, we’re ready for a larger-scale evaluation across all of our target models!
Launching an evaluation
Chalk's Prompt Evaluation abstracts away the boilerplate of evaluation. You only specify the key components:
- prompts: The list of Chalk prompts to use for the evaluation.
- dataset_name: The name of the input Dataset to use for the evaluation.
- reference_output: The name of the feature to use as the reference output for the evaluation.
- evaluators: The list of evaluation functions to use for the evaluation. The functions could be a custom or Chalk defined-evaluators, e.g. “exact_match”.
import chalk.prompts as P
completion_kwargs = {
"messages": [
P.Message(role="system", content=system_message),
P.Message(role="user", content=user_message),
],
"temperature": 0.2,
"max_tokens": 1,
}
gemini_kwargs = {
**completion_kwargs,
"stop": ["\\n"],
}
chalk_client.prompt_evaluation(
dataset_name="nolan_trivia",
evaluators=["exact_match"],
reference_output=NolanTrivia.actual_answer,
prompts=[
P.Prompt(model="gpt-4.1", **completion_kwargs),
P.Prompt(model="gpt-4.1-mini", **completion_kwargs),
P.Prompt(model="gpt-4.1-nano", **completion_kwargs),
P.Prompt(model="gpt-4o", **completion_kwargs),
P.Prompt(model="gpt-4", **completion_kwargs),
P.Prompt(model="gpt-4-turbo", **completion_kwargs),
P.Prompt(model="gpt-3.5-turbo", **completion_kwargs),
P.Prompt(model="claude-sonnet-4-20250514", **completion_kwargs),
P.Prompt(model="claude-opus-4-20250514", **completion_kwargs),
P.Prompt(model="claude-3-7-sonnet-20250219", **completion_kwargs),
P.Prompt(model="claude-3-5-sonnet-20241022", **completion_kwargs),
P.Prompt(model="claude-3-5-haiku-20241022", **completion_kwargs),
P.Prompt(model="claude-3-haiku-20240307", **completion_kwargs),
P.Prompt(model="gemini-2.0-flash", **gemini_kwargs),
P.Prompt(model="gemini-2.0-flash-lite", **gemini_kwargs),
P.Prompt(model="gemini-1.5-pro-002", **gemini_kwargs),
P.Prompt(model="gemini-1.5-flash", **gemini_kwargs),
],
)The prompt_evaluation function abstracts away the boilerplate. It loads the dataset, uses the prompts to fill out all the appropriate completion calls with jinja templating, unfolds usage and runtime statistics in their own columns, and compares the response with reference output.
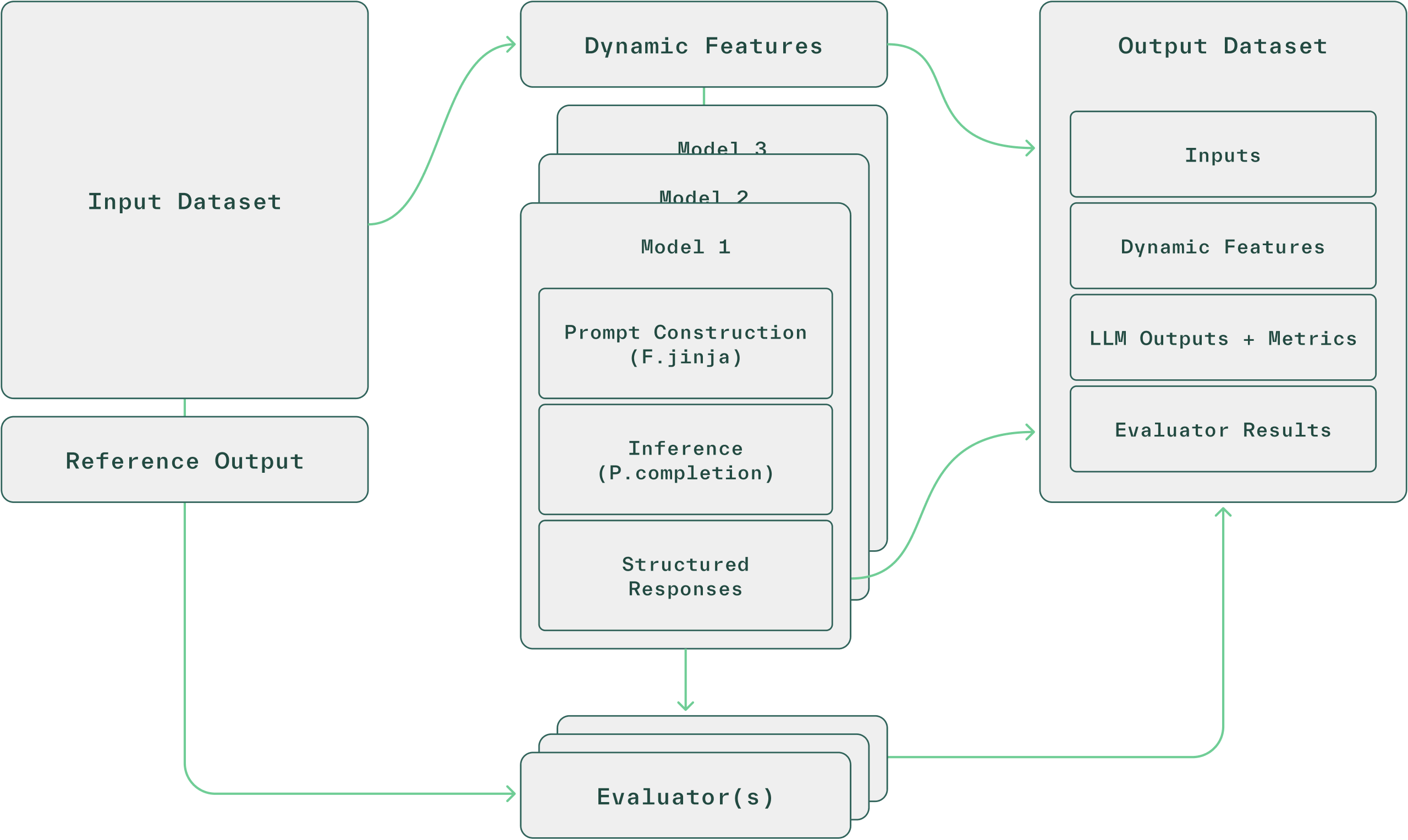
The result of this function is reference to another Chalk Dataset that we could load into a notebook and perform some analysis, but the Chalk Dashboard also presents this information neatly.
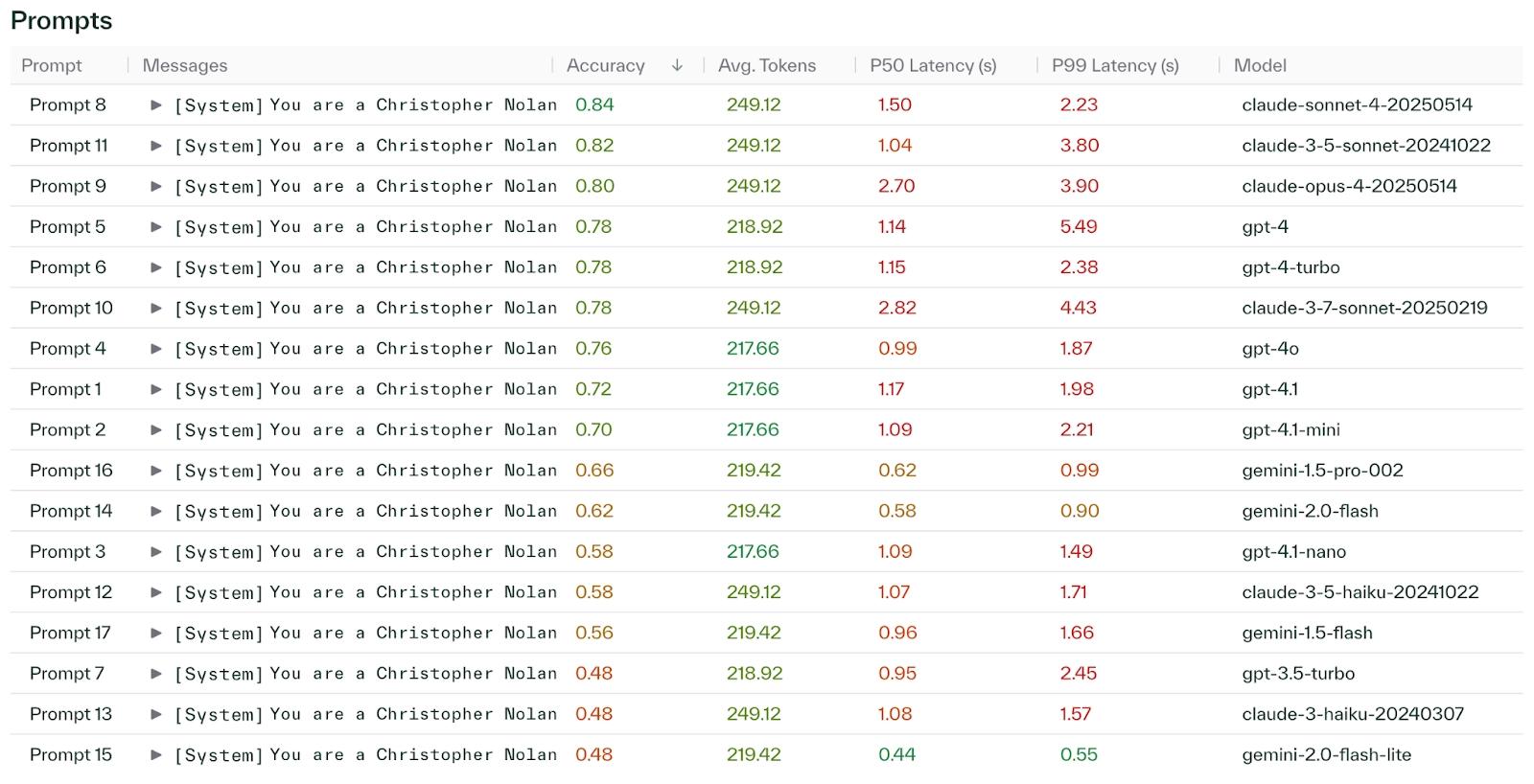
And the winner of the trivia challenge? Claude Sonnet 4—a true Nolanite.
Deploying the winner
Deploying the best-performing prompt is as simple as adding it to your feature model and running chalk apply. You now have a production-ready LLM feature running alongside your other features—backed by the same evaluation lineage and observability stack.
from chalk.features import features
@features
class NolanTrivia:
id: int
question: str
actual_answer: str
llm_answer: P.PromptResponse = P.completion(
model="claude-sonnet-4-20250514",
messages=[
P.message(role="system", content=system_message),
P.message(role="user", content=F.jinja(user_message)),
],
temperature=0.2,
max_tokens=1,
)Why native evaluation matters
Prompt engineering today is often a manual process: iterating in notebooks, trying prompt variants, copying responses to spreadsheets, and judging outputs by eye. That might work for toy tasks—but in production, you need measurement, reproducibility, and iteration at scale.
Chalk’s native prompt evaluation framework turns LLM development into a first-class engineering discipline. By treating prompts as structured, versioned artifacts and combining them with dataset-backed metrics, developers can:
- A/B test prompts and models
- Optimize for cost and latency
- Trace evaluation lineage
- Deploy with confidence
In this demo, we used a single prompt template across providers, but there’s more dimensions to explore: per-model prompt tuning, parameter sweeps, embedded context, retrieval, and even tool-use to surf the web.
Latency and cost are also key deployment considerations. Chalk surfaces these metrics directly during evaluations, giving teams the visibility to make informed tradeoffs—without additional logging infrastructure.
At Chalk, we want ML teams to focus on innovating on their ideas, while we take care of details under the hood to optimize your compute workloads and surface insights. From feature computation to model inference to LLM prompt evaluation—we’ve built the tools to unify your stack, simplify your workflows, and move from experiment to production with speed and reliability.





