

This quarter, we expanded Chalk across three core dimensions: flexibility, visibility, and efficiency. Teams can now define and serve models alongside features, trace query behavior for diagnosis, and adapt feature logic dynamically without redeploying.
These updates extend Chalk’s reach as a data platform for AI and ML, unifying how teams build, deploy, and observe systems for production and training.
Here’s what’s new.
Register and serve models alongside your features
Chalk supports registering and running models directly in Python. Models are type-checked against their inputs and outputs, and referenced by stable names in Named Queries.
This allows teams to track, version, and serve models in the same workflows they use for features. Model registration reduces infrastructure overhead and keeps training, batch, and live inference consistent by design.
Read more about model registry in our docs. Reach out to our team if this is something you are interested in adopting.
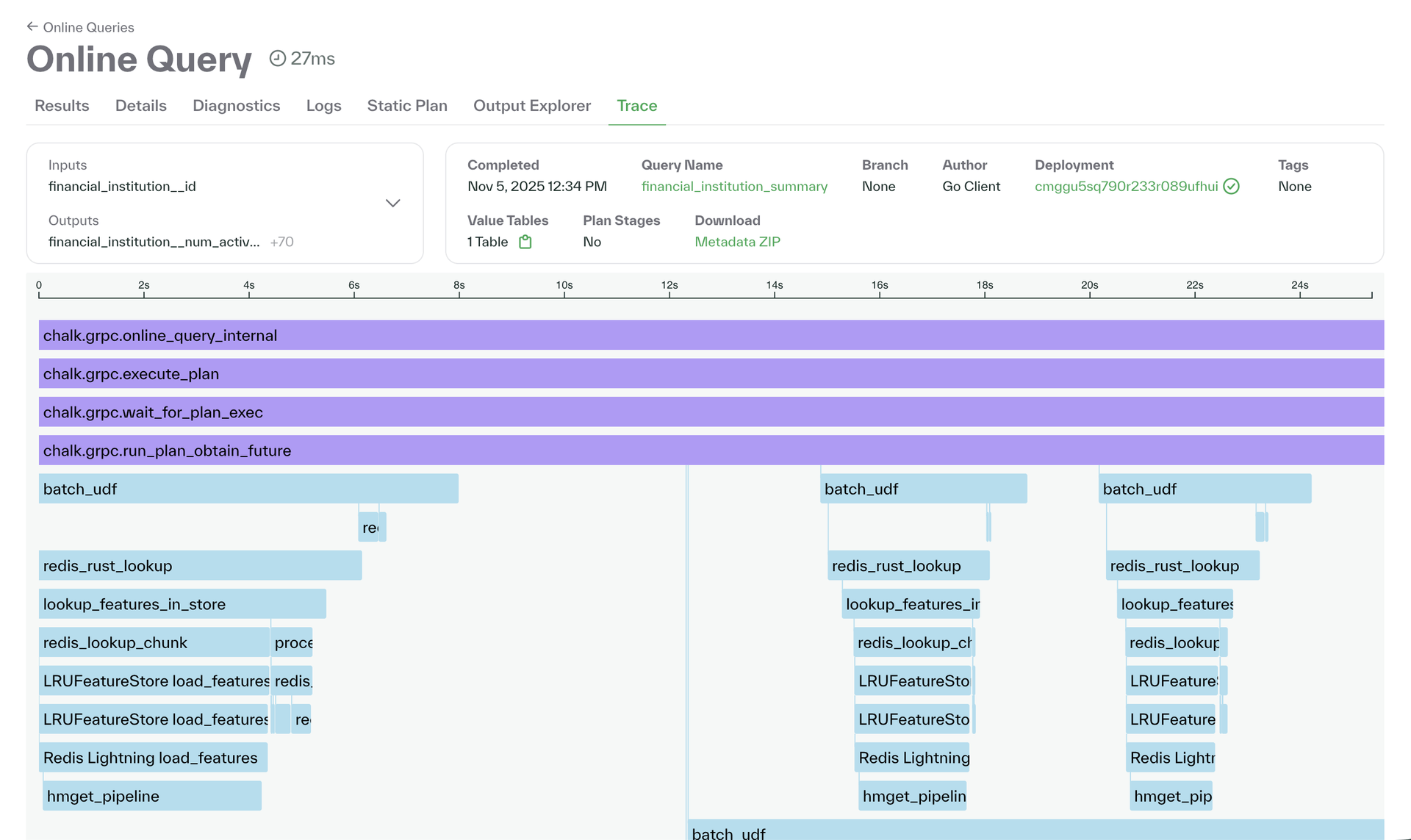
Tracing for query performance diagnosis
Tracing gives teams deep visibility into how queries run inside Chalk. Each resolver and model call is instrumented and timed, making it easy to identify performance bottlenecks and understand why a query behaves the way it does. By surfacing this data directly in the dashboard, Chalk helps teams diagnose and optimize production systems with precision.
Traces can be enabled per query through the CLI --trace or configured to sample automatically in production. This allows high-volume teams to monitor performance continuously without overhead.
Vector aggregations for embedding workflows
Chalk has improved support for vector search and implemented vector aggregations like vector_sum and vector_mean, enabling teams to compute over sequences of embedded features within Chalk.
These capabilities power use cases like recommendation systems and fraud clustering, where teams need to perform time-decaying nearest neighbor retrieval or compute rolling representations of user behavior over time. By operating on vectors natively, teams can simplify architecture and reduce inference latency without leaving Chalk.
@features
class Transaction:
id: int
...
embedding: Vector[384]
@features
class User:
id: int
transactions: DataFrame[Transaction]
...
mean_embedding: Windowed[Vector[384]] = windowed(
"30d", "60d", "90d",
materialization={"bucket_duration": "1d"},
# Vector mean will be computed as the element-wise
# mean for each component of the vector
expression=_.transactions[_.embedding].mean(),
default=Vector(np.zeros(384, dtype=np.float16)),
)These operations often feed model inputs for retrieval and ranking tasks and integrate cleanly with Chalk’s model registry and inference workflows.
Dynamic Expressions for runtime logic
Production feature sets increasingly require runtime variation without redeployment. Dynamic Expressions allow feature logic to be computed at query time instead of only at deploy time.
With this capability, you can overlay context‑specific rules, support hot‑fixes, and run time‑aware logic without additional releases.
We also expanded the expression library with:
- Over 50 new Velox functions, including
max_by_n,min_by_n, and aggregations likeapprox_top_k - Support for sklearn classifiers, now hostable directly in Chalk
These updates make feature logic more expressive while maintaining type safety and performance.
result, err := client.OnlineQueryBulk(
t.Context(),
chalk.OnlineQueryParams{}.
WithInput("user.id", []int{1}).
WithOutputs("user.name").
WithOutputs("user.email").
WithOutputExprs(
expr.FunctionCall(
"jaccard_similarity",
expr.FunctionCall("lower", expr.Col("name")),
expr.FunctionCall("lower", expr.Col("email")),
).
As("user.name_email_sim"),
),
)Improved diffs and offline input visibility
Production ML systems require strong introspection into what changed, what ran, and why. This quarter, we focused on surfacing that context more clearly across environments, deployments, and queries.
- The improved diff viewer now renders full file contents when resolvers or features are added, removed, or modified. This makes it easier to review code changes, compare logic between branches, and trace regressions back to specific changes.
- Dashboard metadata now includes runtime details like service account, namespace, and role ARN. This makes it easier to understand which services are running where, and under which policies.
- Offline Inputs Explorer now shows the raw SQL and parameters used to build datasets. This supports validation of training workflows and better visibility into how feature inputs are sourced.
Prompt templates for Cursor and Claude via CLI
We added a new CLI workflow to help teams quickly generate structured prompt templates for LLM-assisted development. Running chalk init agent-prompt scaffolds prompt definitions that work with tools like Cursor or Claude and provide context on Chalk-specific syntax, including:
- Creating feature classes and joins
- Writing python and SQL resolvers
- Adding unit and integration tests
These templates help teams standardize development workflows and accelerate onboarding with built-in Chalk best practices. Templates are here.
Chalk in production: recsys, credit decisioning, and underwriting
World class teams continue to adopt Chalk across industries where real-time decisions matter.
- Whatnot uses Chalk to power real-time recommendations across its live streaming marketplace, from feed ranking to show discovery. Read or watch their story here.
- iwoca, one of Europe's leading small business lenders, adopted Chalk for its compute-first architecture to unify training and production pipelines, reduce drift, and make data consistency a system-level guarantee. Read their story here.
- Mission Lane helps Americans build better financial futures by making credit more accessible. In a recent live demo, their Head of Data Science and ML showed how they manage thousands of features across training, live decisioning, and batch workflows, cutting rollout time from weeks to days. Watch it here.
Learning & deep‑dive resources
To help teams understand where and how Chalk fits into ML stacks, we published:
- Chalk for data engineers: How to productionize features using Chalk’s Python interface without managing separate pipelines for training, serving, and batch workflows.
- Chalk for data scientists: How to prototype features, run experiments, and deploy models with consistent features across training and production.
- Chalk’s YouTube channel: Architecture deep‑dives, customer demos, and walkthroughs.



