

Machine learning has long been deeply embedded in the field of fraud detection. Data science and engineering teams continue to develop increasingly sophisticated models for detecting fraud in real-time, which is vital for many industries, especially fintech. Production machine learning platforms power a majority of financial interactions across the world, making the infrastructure on which these models and platforms rely imperative.
At the heart of machine learning infrastructure is the feature store. Feature stores enable data scientists, data engineers, and software engineers to extract accurate, real-time features, develop and iterate on machine learning models, and maintain historical stores of features past for training and compliance purposes. In this article, we will walk through a simplified version of a machine learning platform targeting fraud risk detection to expose how each component of the feature store fits together to facilitate a better fraud risk model.
For a detailed dive into the architecture of a feature store, please refer to What is a Feature Store?
High-Level Architecture
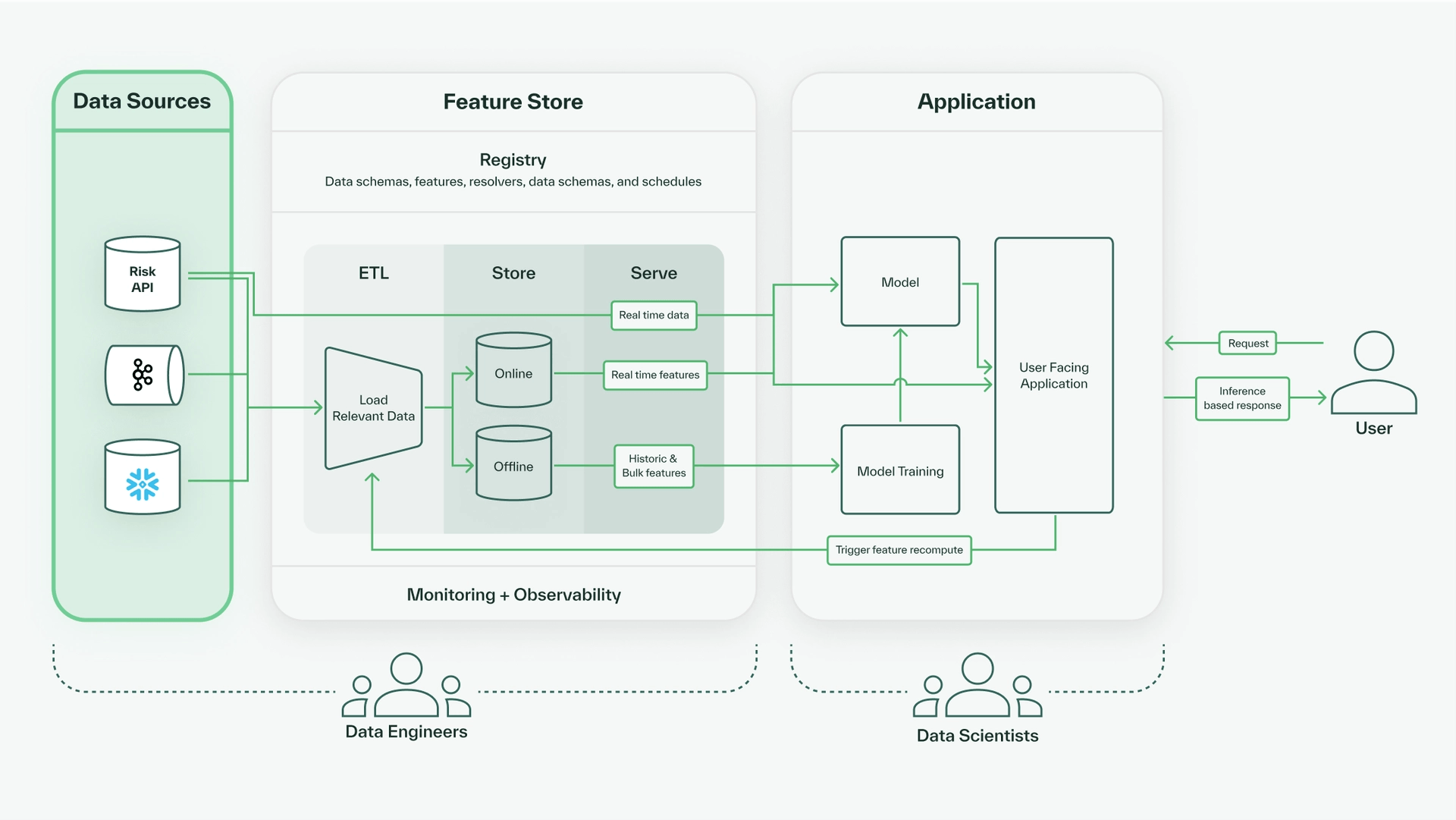
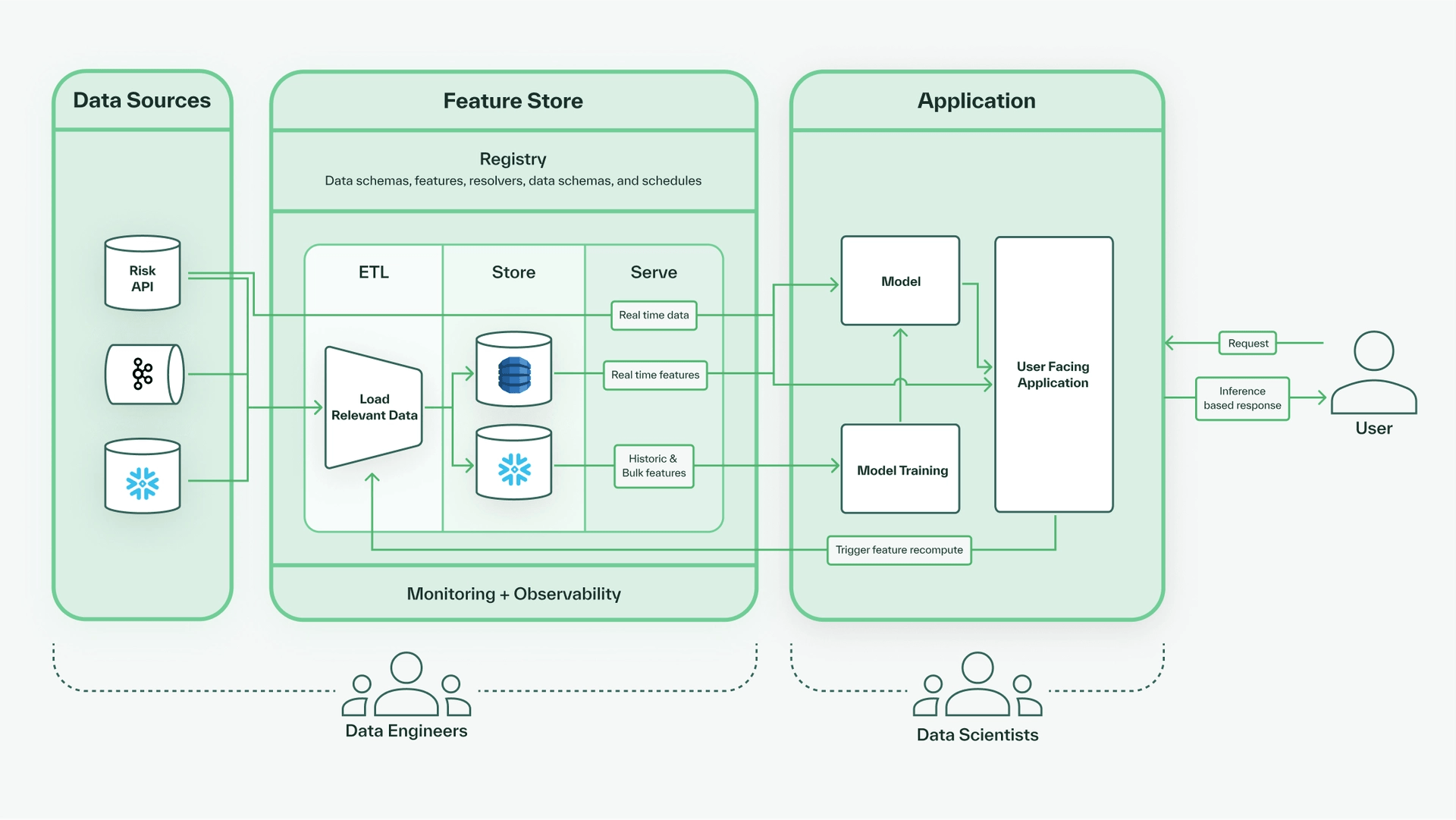
The feature store lives between raw data sources, machine learning models, and applications. The schema of a feature store is called a registry, which defines the names and types of features. Once the features are defined in the registry, the core data flow determines how the features are computed. On top of that lives the monitoring and observability system that exports metrics used to detect and prevent problems like feature drift.
The core data flow of a feature store can be divided into three parts.
- ETL (Extract, Transform, Load): First, we load data from our raw data sources into the feature store. Our features can be directly loaded from the sources or require some computation based on the schema definitions in the registry, so we extract, optionally transform, and then load data into our stores.
- Store: Within a feature store there are two forms of storage–-an online store and an offline store. The online store acts as a cache, serving recently or freshly computed real-time feature values with low latency. Meanwhile, the offline store handles large data volumes, usually storing historical feature values used for machine learning model training and data governance purposes.
- Serve: The feature store serves data in response to queries. Depending on the query specifications, the data served may either be previously stored data living in the online or offline store, or it could be freshly computed on-demand feature values that reflect real-time data.
The full flow of data in a machine learning platform is illustrated below, from the data sources, to the feature store, to the features served and used in the application.

To illustrate how a feature store enables production machine learning platforms to handle fraud detection use cases, we will step through each portion of this data flow, starting with the raw data sources.
Raw Data Sources
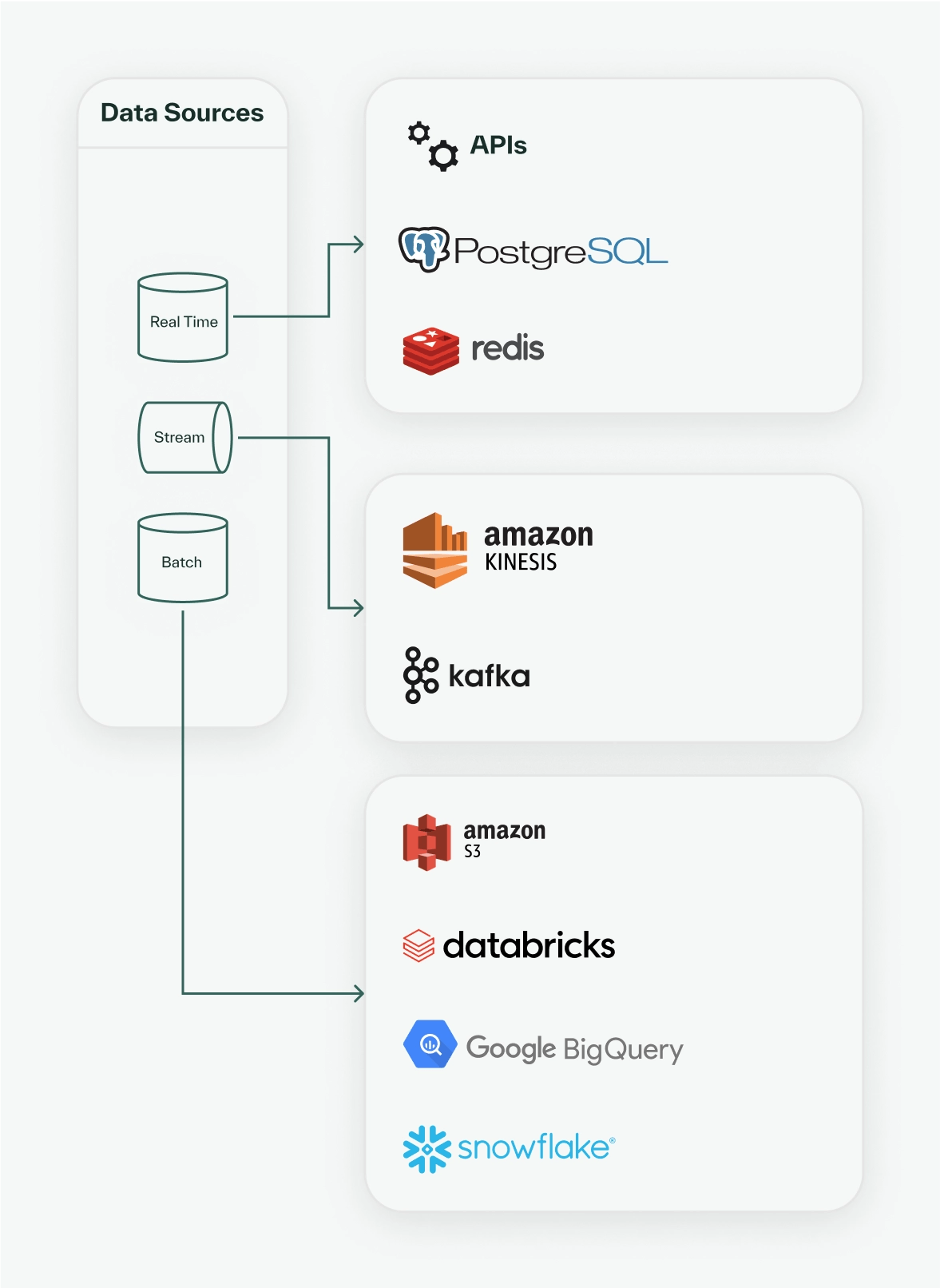
A feature store integrates with your existing architecture. The first step in setting up a feature store for your machine learning platform is to define which raw data sources you want to connect. For this fraud detection model, we will use user and financial transaction data. First, we define a Kafka streaming source for live transaction data, as well as a Snowflake batch data source for enriched, historical transaction and user data.
from chalk.sql import SnowflakeSource
from chalk.streams import KafkaSource
kafka = KafkaSource(name="txns_data_stream")
snowflake = SnowflakeSource(name="user_db")Then, we can use a real time data source, Risk API, to fetch live user risk scores.
Once we have authenticated our feature store to each of these data sources, we’re ready to start defining features!
Feature Store
To construct our feature store, we can begin by defining the registry, which serves as a framework on top of which our core data flow will live, and finally define key alerting threshold for observability.
Feature Store: Registry
For our fraud use case, we will focus on two feature sets: User and Transaction. We define these feature sets, along with some resolver definitions for features, in the code below.
from chalk.features import features, FeatureTime
from chalk.streams import Windowed, windowed
@features
class User:
id: int
first_name: str
last_name: str
email: str
address: str
country_of_residence: str
# these windowed features are aggregated over the last 7, 30, and 90 days
# avg_txn_amount computes the average of transaction.amount over each time period
# num_overdrafts computes the number of transactions where
# transaction.is_overdraft == True over each time period.
avg_txn_amount: Windowed[float] = windowed("7d", "30d", "90d")
num_overdrafts: Windowed[int] = windowed("7d", "30d", "90d")
risk_score: float
# transactions consists all Transaction rows that are joined to User
# by transaction.user_id
transactions: "DataFrame[Transaction]"
@features
class Transaction:
# these features are loaded directly from the kafka data source
id: int
user_id: User.id
ts: FeatureTime
vendor: str
description: str
amount: float
country: string
is_overdraft: bool
# we compute this feature using transaction.country and
# transaction.user.country_of_residence
in_foreign_country: bool = _.country == _.user.country_of_residence
Several features can be copied directly from the raw data source. We also use expression notation to define simple features, such as transaction.in_foreign_country. For the remainder of our features, we still need to define resolvers. We dictate how to load and transform data from our data sources into feature values using SQL resolvers or Python resolvers.
The following SQL resolver loads existing columns from our Snowflake data source and maps them to the corresponding User features.
-- resolves: User
-- source: user_db
select id, email, first_name, last_name, address, country_of_residence
from user_dbThe following Python resolver loads transactions from our Kafka streaming source and maps them to Transaction features.
from pydantic import BaseModel
from datasources import kafka
from chalk.streams import stream
# Pydantic models define the schema of the messages on the stream.
class TransactionMessage(BaseModel):
id: int
user_id: int
timestamp: datetime
vendor: str
description: str
amount: float
country: str
is_overdraft: bool
@stream(source=kafka)
def stream_resolver(message: TransactionMessage) -> Features[
Transaction.id,
Transaction.user_id,
Transaction.timestamp,
Transaction.vendor,
Transaction.description,
Transaction.amount,
Transaction.country,
Transaction.is_overdraft
]:
return Transaction(
id=message.id,
user_id=message.user_id
ts=message.timestamp,
vendor=message.vendor,
description=message.description,
amount=message.amount,
country=message.country,
is_overdraft=message.is_overdraft
)
We now have resolvers to compute all feature values that match data in our raw data sources. All that’s left is to define the resolvers for our remaining features.
from chalk import online, DataFrame
from kafka_resolver import TransactionMessage
from risk import riskclient
@online
def get_avg_txn_amount(txns: DataFrame[TransactionMessage]) -> DataFrame[User.id, User.avg_txn_amount]:
# we define a simple aggregation to calculate the average transaction amount
# using SQL syntax (https://docs.chalk.ai/docs/aggregations#using-sql)
# the time filter is pushed down based on the window definition of the feature
return f"""
select
user_id as id,
avg(amount) as avg_txn_amount
from {txns}
group by 1
"""
@online
def get_num_overdrafts(txns: DataFrame[TransactionMessage]) -> DataFrame[User.id, User.num_overdrafts]:
# we define a simple aggregation to calculate the number of overdrafts
# using SQL syntax (https://docs.chalk.ai/docs/aggregations#using-sql)
# the time filter is pushed down based on the window definition of the feature
return f"""
select
user_id as id,
count(*) as num_overdrafts
from {txns}
where is_overdraft = 1
group by 1
"""
# the cron notation allows us to run this resolver on a schedule
# this resolver is currently set to run daily
# https://docs.chalk.ai/docs/resolver-cron
@online(cron="1d")
def get_risk_score(
first_name: User.first_name,
last_name: User.last_name,
email: User.email,
address: User.address
) -> User.risk_score:
# we call our internal Risk API to fetch a user's latest calculated risk score
# based on their personal information
riskclient = riskclient.RiskClient()
return riskclient.get_risk_score(first_name, last_name, email, address)
We have now completed defining our registry! Next, we can choose the storage component of our feature store.
Feature Store: Core Data Flow
The registry defines the schema for the first and last stage of the core data flow in a feature store–namely how we ETL (extract, transform, and load) data into the store and what features we will serve. Then the missing piece at the center is choosing which storage providers to use for the online and offline store. There are a few common choices optimized for performant cache reads for the online store and bulk storage for the offline store shown below.
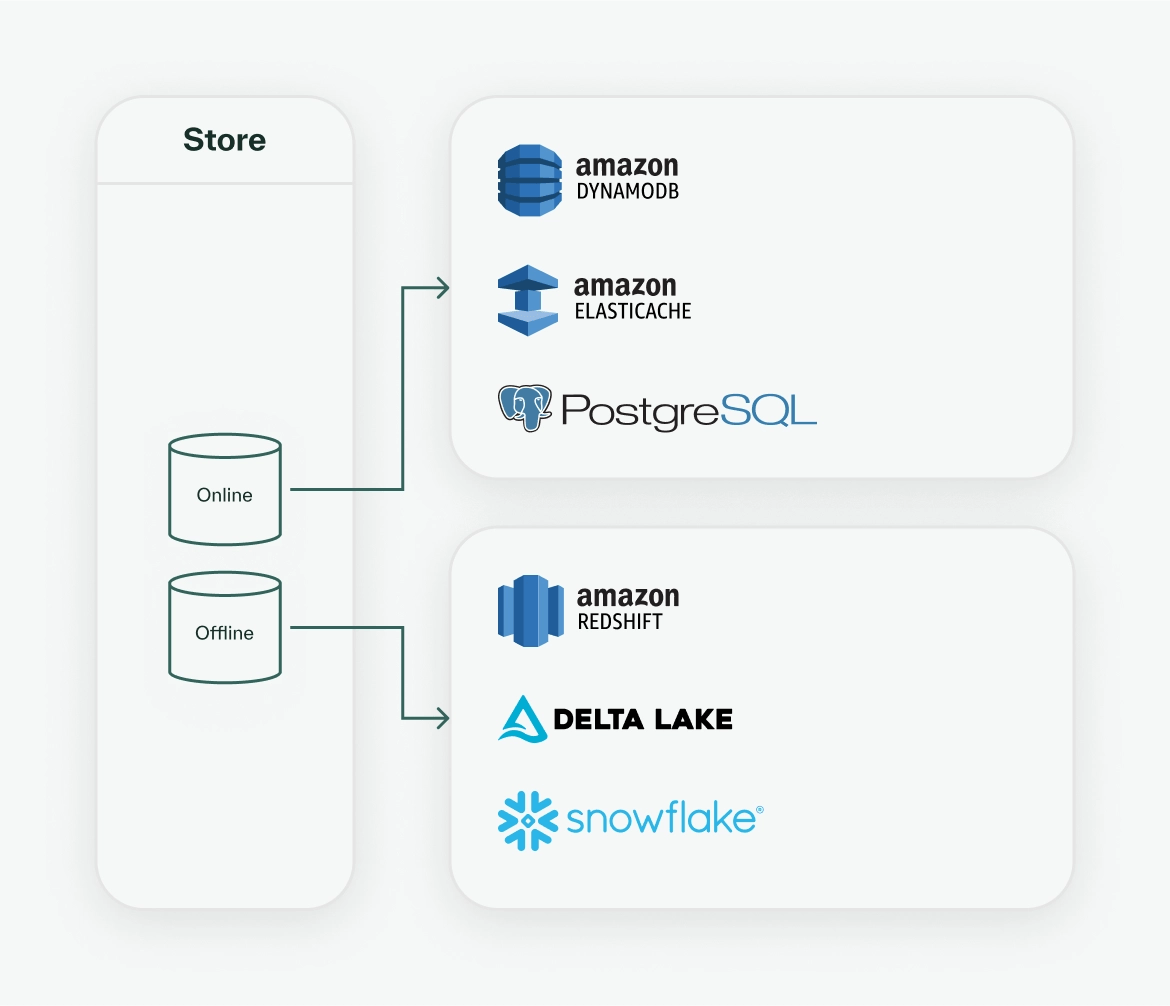
For this use case, let us use DynamoDB for the online store and Snowflake for the offline store. This completes the core data flow of the feature store!
Feature Store: Monitoring and Observability
Observability is required for all production systems, and feature stores are no exception. Feature stores provide a number of metrics that are useful for monitoring data quality.
Given that we have a streaming source and a scheduled resolver, we can choose to monitor a few key metrics:
resolver_high_water_mark: we would want to determine the latest time stamp up to which we have loaded data from our streaming data source to ensure that we are not missing transaction data and to detect any issues with the stream.cron_feature_writes: we can track the number of features written by our scheduler resolver to ensure that we’re consistently updating user risk scores with the latest data from our internal Risk API.feature_value: we track the distribution of feature values over time to detect issues like feature drift, where small changes in accuracy of feature values can result in big impacts to our risk models.
Thus, having defined our registry, core data flow, and observability metrics, we have all we need within our feature store to start to use it for our fraud risk detection model and application.
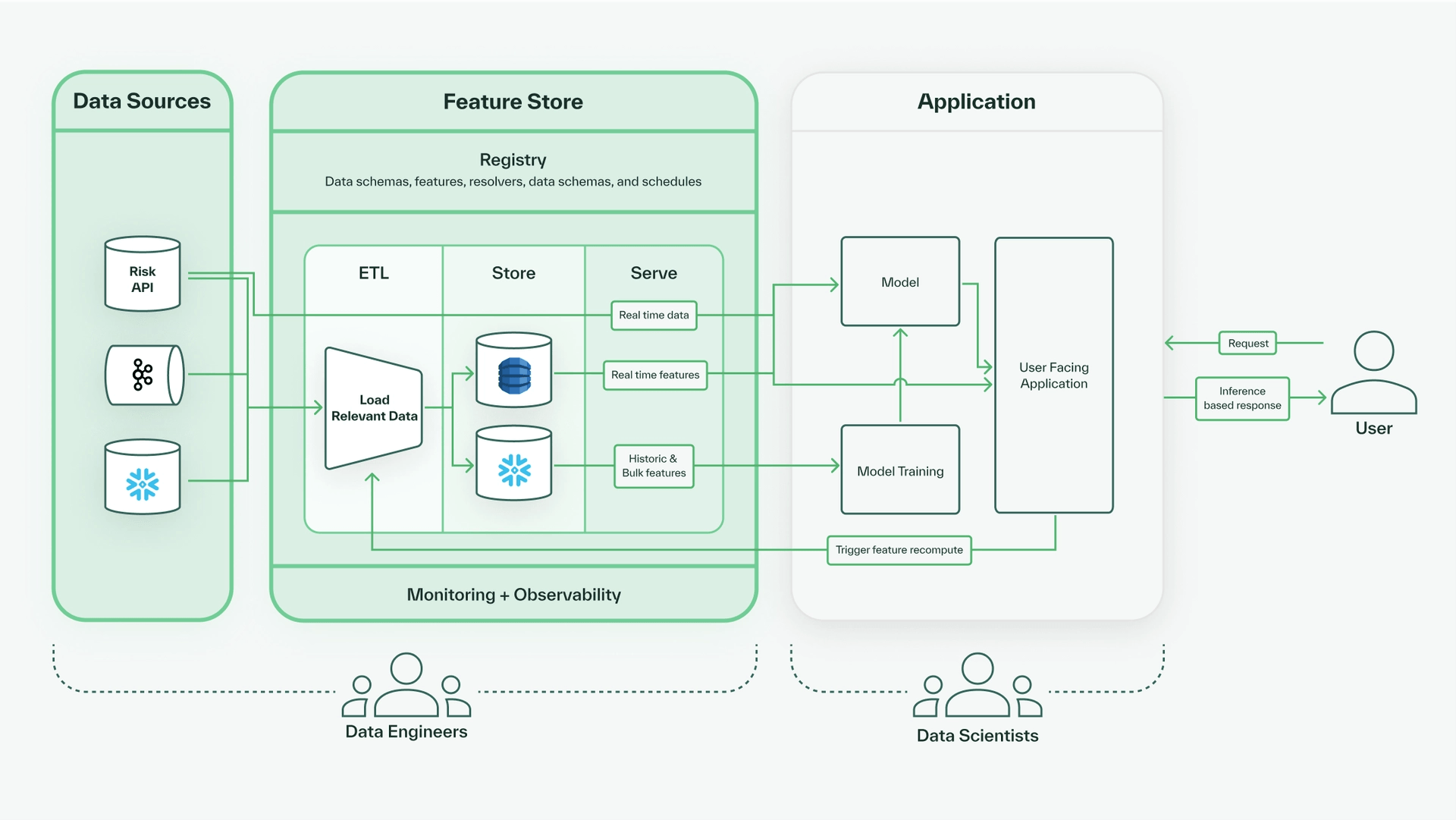
Application: Querying the Feature Store
Having configured the raw data sources and the different components of the feature store, we can now fetch feature values on demand through online and offline queries. Generally, online queries are used to fetch real-time feature values for live inference models and serving applications, whereas offline queries are used to query bulk and/or historical data, often for the development and training of machine learning models.
For our fraud detection use case, the first step is querying features that we will use to train our machine learning models. Let’s say for a list of users, we want to query the risk scores, as well as the average transaction amounts and number of overdrafts in the last 7 days.
from chalk.client import ChalkClient
from src.models import User
user_ids = [1093485493, 1093495732, 1029436728]
dataset = ChalkClient().offline_query(
input = {
User.id: user_ids,
User.ts: datetime.now() * len(user_ids),
},
output = [
User.country_of_residence,
User.risk_score,
User.avg_txn_amount["7d"],
User.num_overdrafts["7d"],
],
recompute_features = True,
)
To understand what happens when we run this query, we should think about how data is populated into the offline store. When we define resolvers, we can define them as @online or @offline based on how the features will be computed. Online resolvers are usually run on-demand, while offline resolvers are run to pre-compute features. A resolver will run either on a cron schedule, when it is triggered either manually, or by an orchestrator like Airflow.
During a query, the feature store will use the resolver definitions to create a plan of which computations to run and in what order to determine all the outputs queried for the given inputs. Online queries may load data that is already cached in the online store, and offline queries may load already computed data from the offline store, but both types of queries can also serve real-time computed-on-demand feature values.
In our query above, because we request recompute_features=True, the feature store recomputes all the feature values, so we have the most up-to-date data. So, the feature store will hit the Risk API and load and recompute feature values from our Snowflake (our batch data source) to determine the values for all the output features, which are served to the user to use in training and stored in the offline store. This data flow is illustrated below.
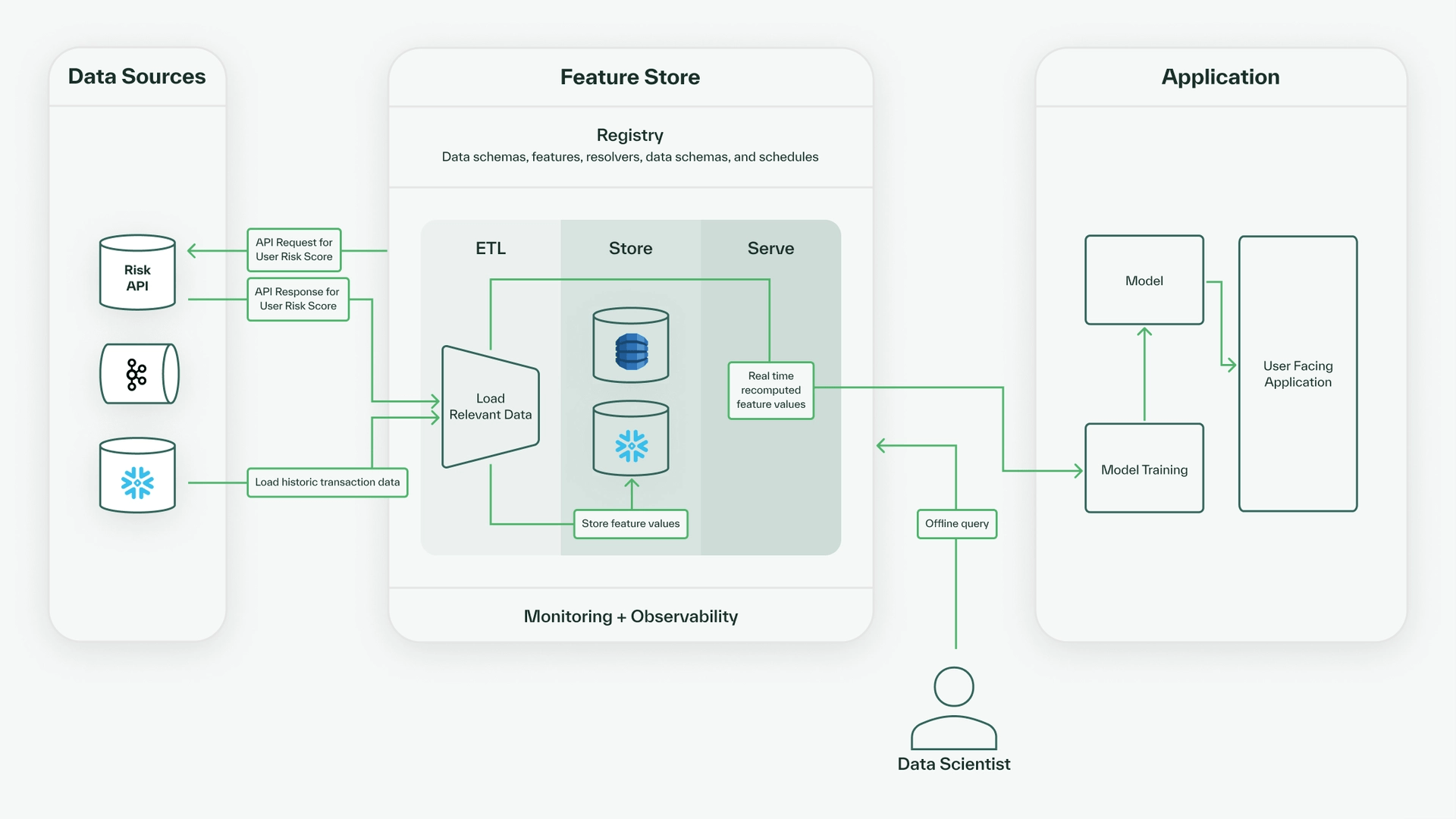
The output for this query would look something like this:
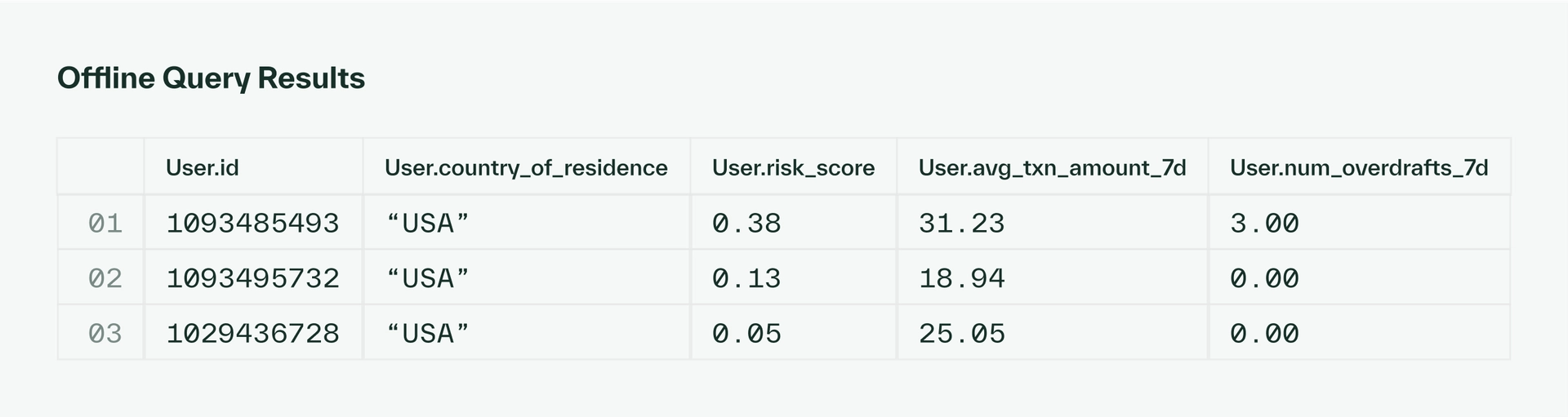
We can use these features to train our fraud risk model. To obtain the latest training data, we can schedule offline queries to ingest the latest relevant feature values into the offline store daily.
Then, to use the fraud risk model to make real-time inference decisions to determine whether incoming transactions might be fraudulent, we can use an online query to fetch the relevant features for a user.
from chalk.client import ChalkClient
from src.models import User
user_features = ChalkClient().query(
input = {User.id: 1093485493},
output = [
User.id,
User.first_name,
User.last_name,
User.country_of_residence,
User.risk_score,
User.avg_txn_amount["7d"],
]
)
As a result of this query, we would get the following:
{
user.id: 1093485493
user.first_name: "Melanie"
user.last_name: "Chen"
user.country_of_residence: "USA"
user.risk_score: 0.38
user.avg_txn_amount_7d: 31.23
}Since we want the online query to be low latency, we can also ingest the relevant feature values into the online store through a daily scheduled resolver run. Then, to determine whether an incoming transaction is fraudulent, we could run this online query to fetch the relevant user data, pass the user data and incoming transaction data into the model, and return a fraud risk decision in our application. The full flow of data for calculating the real-time fraud risk of a transaction looks like this.
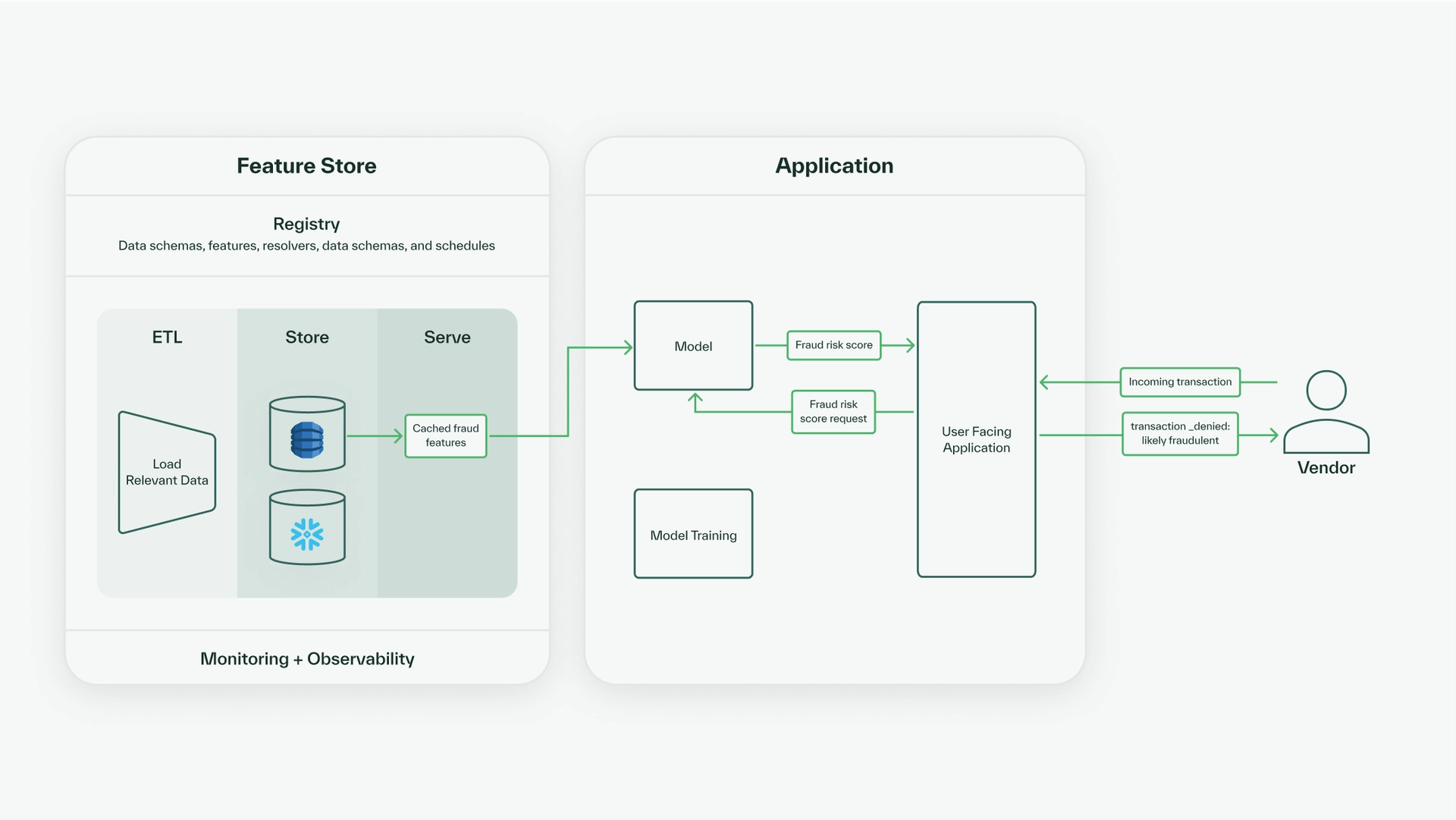
Thus, with our machine learning-powered application serving live fraud risk scores as computed using the features from our feature store, we have stepped through each component of a machine learning platform with a feature store.
Conclusion
In this case study, we demonstrate how a feature store can enable the development and deployment of machine learning models for real-time fraud risk detection in financial applications. Feature stores enable better collaboration between teams and the development of better machine learning models and products by centralizing the definition of key machine learning features and datasets. Fraud risk detection is just one of countless use cases where production machine learning teams can incorporate a feature store to improve their platform.
Chalk offers a data source agnostic feature store, with clients in multiple programming languages, and lightning-fast deploys and queries. Developers love Chalk’s best-in-class feature store. To see for yourself, please book a demo.




