Chalk for Data Scientists
Discover and create features, generate reproducible datasets, and accelerate AI and ML experiments with Chalk.
TALK TO AN ENGINEER

Trusted by teams building the next generation of AI + ML
Why data scientists
choose Chalk
Why data scientists
choose Chalk
Data Scientists move quickly from hypothesis to production. With Chalk they:
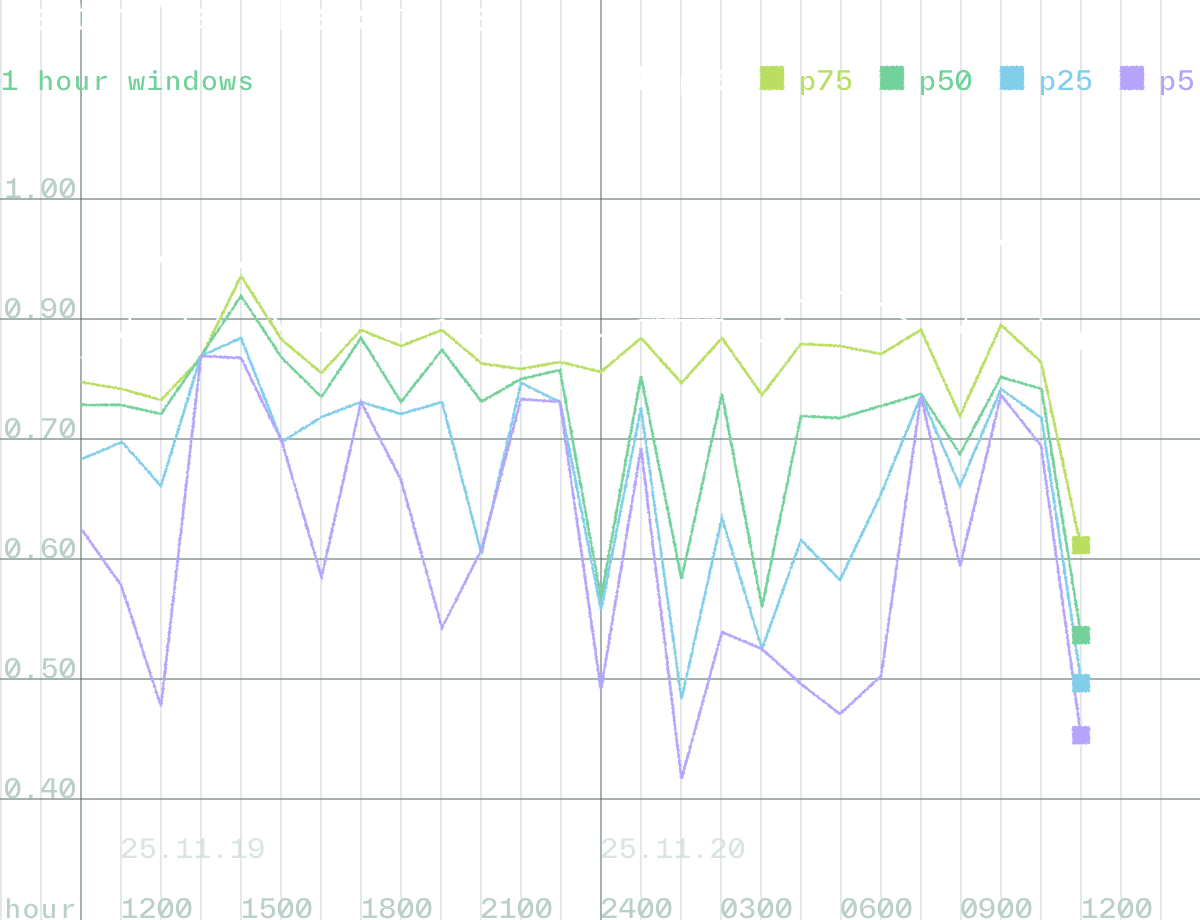
- Get observability into the features they serve
- Build training datasets with lineage
- Trust that training and production always stay in sync
By moving our feature pipelines to Chalk, Data Science and Engineering now work side-by-side throughout model development. What used to be lengthy, error-prone handoffs are gone. Our entire search ranking stack runs on Chalk, serving features for inference in under 50ms, and we’re extending it to all of our models, including real‑time personalization.
Moaj Mustang Head of Engineering
Point-in-time correctness
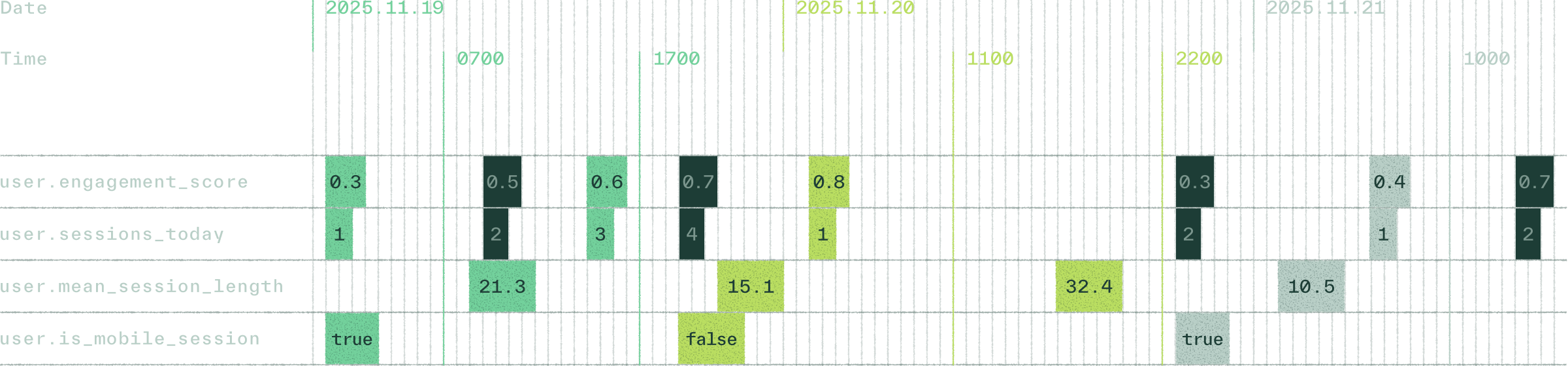
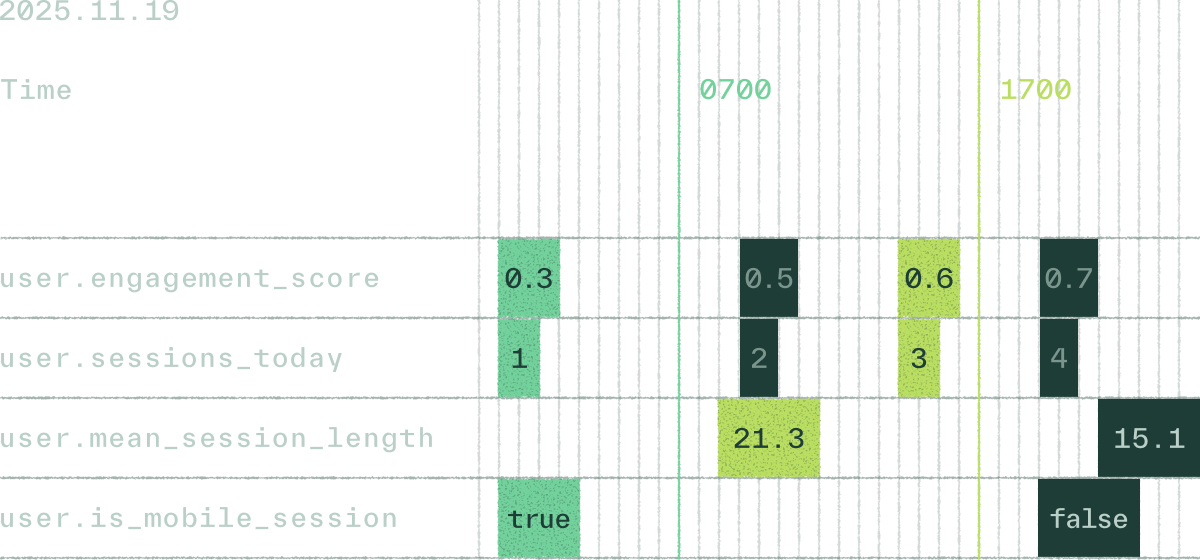
Training data should reflect what your application would have known at the time. Chalk guarantees this with point-in-time lookups:
- Avoid leakage by using only values available at the correct historical moment
- Generate reproducible datasets with complete lineage
- Backtest models with confidence, knowing inputs match production
Built for notebooks
Built for notebooks
Chalk integrates directly with the tools data scientists use every day, enabling them to explore, iterate, and ship models without leaving their notebook.
- Iterate on features and model training directly in your notebook
- Deploy, backfill, and monitor datasets for training pipelines
- Experiment and define new features independently while Chalk handles orchestration
Explore how Chalk works
Ready to ship next‑gen ML?
Talk to an engineer and see how Chalk can power your production AI and ML systems.