

Feature stores have become widely adopted for solving training-serving consistency and enabling feature reuse. They work well for many use cases, but teams often hit challenges when they need real-time features, want to experiment quickly, or scale to more sophisticated ML applications. This is where feature engines come in.
What is a feature store?
A feature store is a centralized system that manages and serves machine learning features for models to make their predictions. It stores features for reuse across training and production, keeping models accurate and reliable.
What is a feature engine?
A feature engine is a computation platform that executes feature logic on-demand, with intelligent caching. It includes all the storage capabilities of a feature store, plus much more.
Key capabilities that feature engines add:
- Fresh data at inference time instead of only batch schedules
- Computation for complex operations in real-time
- Rapid experimentation with instant deployments
- Unified infrastructure combining compute, storage, and monitoring
- Self-service workflows for data scientists
Feature store vs Feature engine
Traditional Feature Store
Chalk Feature Engine
- Features are data records in databases
- Features are Python class attributes with typed definitions
- Stores pre-computed feature values
- Computes features on-demand at query time
- ETL (Airflow/Spark) to offline store → more ETL to sync online store
- Fetches from live data sources, caches as needed, no ETL needed
- Serves stored values without computation logic
- Query planner dynamically optimizes execution paths
- Features get stale in between batch runs
- Features are always fresh from source data
- Need data engineers to set up features and MLOps to productionize new features
- Data scientists can self-serve features and deploy directly with Python
- Testing changes require full pipeline runs
- Branch deployments enable isolated testing and iteration
- Need to set up separate systems for observability
- Built-in monitoring, alerts, feature lineage, and versioning
1. Storage vs. Computation
Feature stores are databases that serve pre-computed values. Feature engines are computation platforms that execute logic on-demand.
When you query a feature store, it looks up a value. When you query a feature engine, it runs a function — traversing dependencies, fetching fresh data, executing transformations. It's like the difference between reading a saved file and running a program.
2. Static vs. Dynamic
Feature stores reliably serve what external systems have computed for them, which works well if your feature definitions rarely change. However, feature stores don't inherently understand your features, they just store what external systems computed. You can't ask "how was this calculated?" or "what would happen if I changed this?".
Feature engines understand the complete computational graph. The feature catalog lets you search and discover all available features, see their usage patterns, and understand dependencies. When debugging, you see the entire path from raw data to the final feature.
3. Pipeline-Dependent vs. Self-Service
With feature stores, changing feature logic (eg. adding a data source) requires data engineers to update ETL pipelines, run backfills, and wait for data to populate—typically hours to days before the feature is usable. This setup makes experimentation especially demanding.
Feature engines transform this workflow. Data scientists write features as Python classes and define logic using three types of resolvers: SQL, Python, and Chalk expressions for optimized operations like windowed aggregations. The engine handles all orchestration. Since features compute on-demand rather than through pipelines, there's no waiting for data to populate.
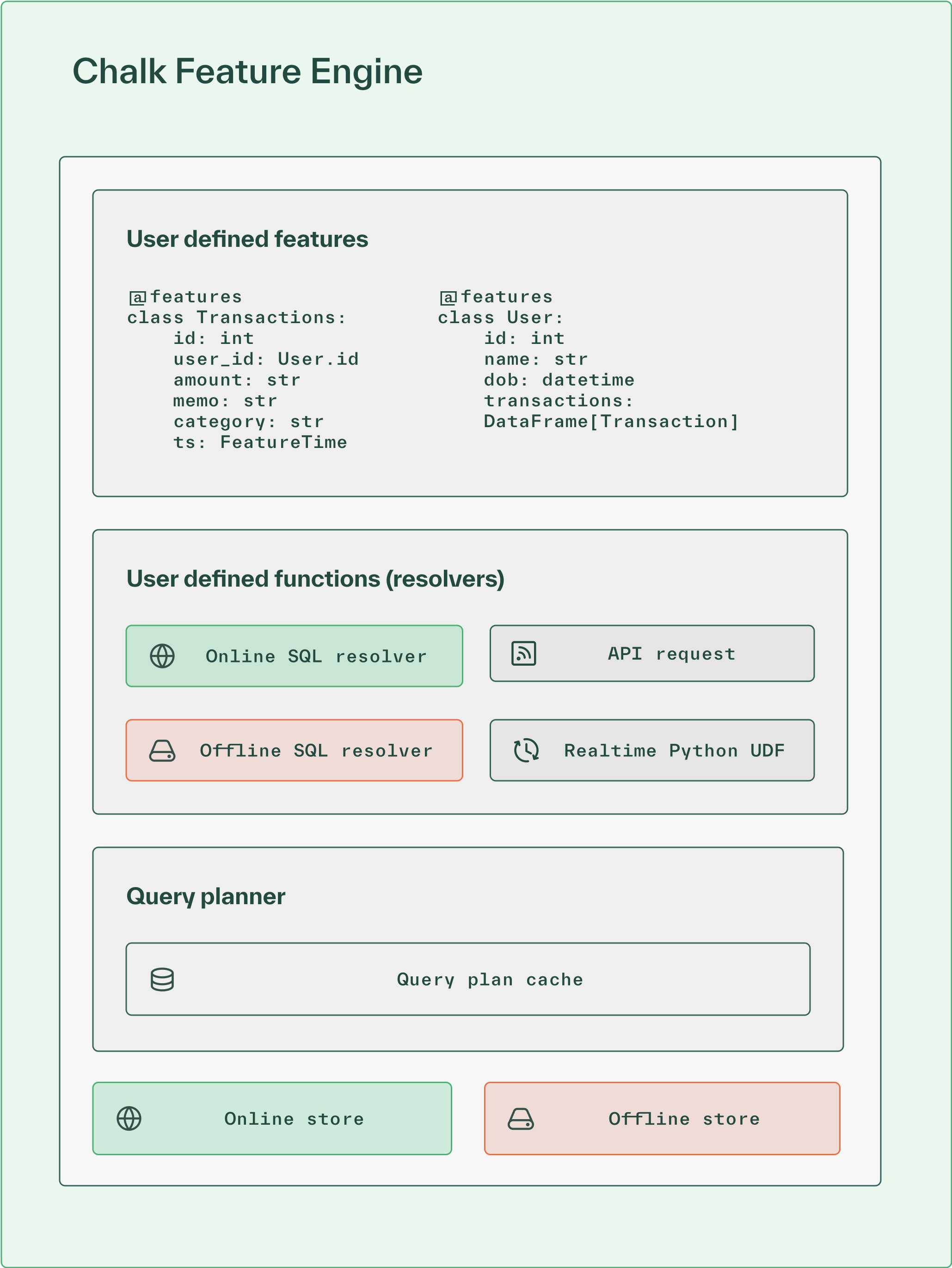
Simply put: feature stores serve pre-computed values and need manual ETL work to sync their online stores. Feature engines compute on-demand and handle both offline and online serving automatically.
Should I use a traditional feature store or feature engine?
If you find yourself duplicating the same logic across different use cases as you add models, it's time to invest in feature infrastructure. It allows you to define features once and reuse them, rather than rebuilding for each model.
Start with a feature store when:
- Simple use case with predictable feature needs
- Batch freshness meets your requirements
Graduate to a feature engine when:
- Use cases demand real-time features served at low-latency
- Multiple teams need reusable features for development velocity
- Data freshness directly impacts model performance
- Infrastructure complexity is slowing speed of experimentation and innovation
The future of feature engineering
Looking ahead, more teams are moving from batch to real-time ML. Batch processing means features are only as fresh as the last pipeline run, limiting model performance for use cases like fraud detection or personalization, where recent user behavior matters.
Developer experience is also improving. Traditional feature stores require coordination between data scientists and engineers to build pipelines and run backfills. Newer systems prioritize self-serve workflows where data scientists can define and deploy features themselves, directly in their notebooks.
Curious how Chalk goes beyond traditional feature stores? Check out our product pages or book a demo.




