

I’m Elvis, developer advocate at Chalk. While attending Data Council last month and engaging in numerous conversations, talks, and demos, I observed several emerging trends:
- Real-time is no longer a nice-to-have but a necessity
- Code-first declarative architectures are replacing manual workflows and ad-hoc scripts
- Python is emerging as the standard programming interface for data tools and platforms
- Builders want a modern yet simple data stack
Let's explore these key themes by looking at innovative startups and new products from the conference that show these trends in action.
Real-time is no longer a nice-to-have but a necessity
Real-time inference stands out as the most dominant trend due to the rise of AI-driven applications and growing user expectations for snappy, responsive product experiences. One of my favorite product launches from the week was MotherDuck's release of "Instant SQL".
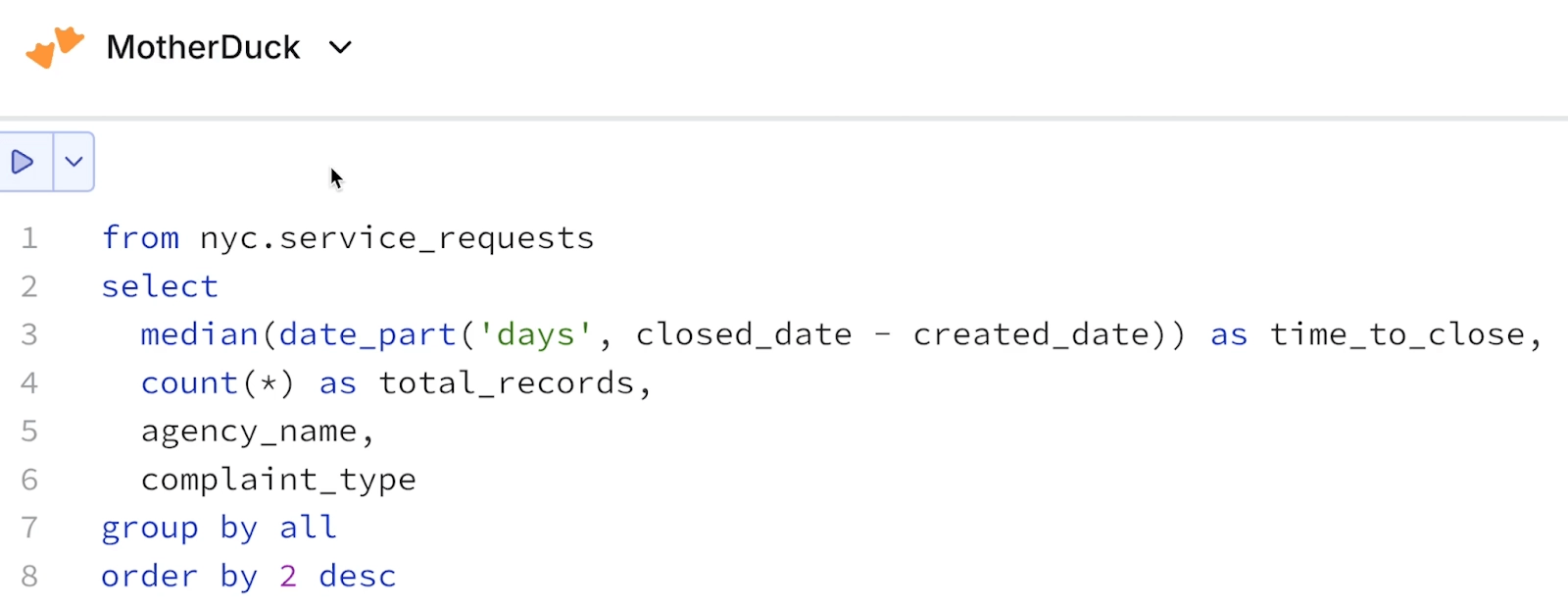
Instant SQL dynamically shows results as you type, transforming the traditional write-run-debug cycle into an interactive, real-time conversation with your data.
Instantly preview and debug each component of your query—from CTEs to complex expressions—to quickly pinpoint issues and maintain an analytical flow state where your best thinking happens.
More than just flashy UX, it works with any data source DuckDB can query—from CSVs to S3 parquet files—and is a strong signal that real-time interactivity is becoming table stakes for next-generation data platforms.
At Chalk, we're witnessing this shift firsthand and expect that it will only accelerate as AI agents increasingly demand fresh context and customers come to expect hyperpersonalized interactions and recommendations.
Code-first declarative architectures are replacing manual workflows and ad-hoc scripts
The second shift is architectural: teams are moving away from drag-and-drop graphical user interfaces (GUIs) and toward code-first, declarative systems that bring the ergonomics of infrastructure-as-a-code (IaaC) to data management.
Rill is a perfect example of this trend, using SQL as the primary language to build dashboards while streamlining the entire journey from data exploration to metrics visualization in a single tool.
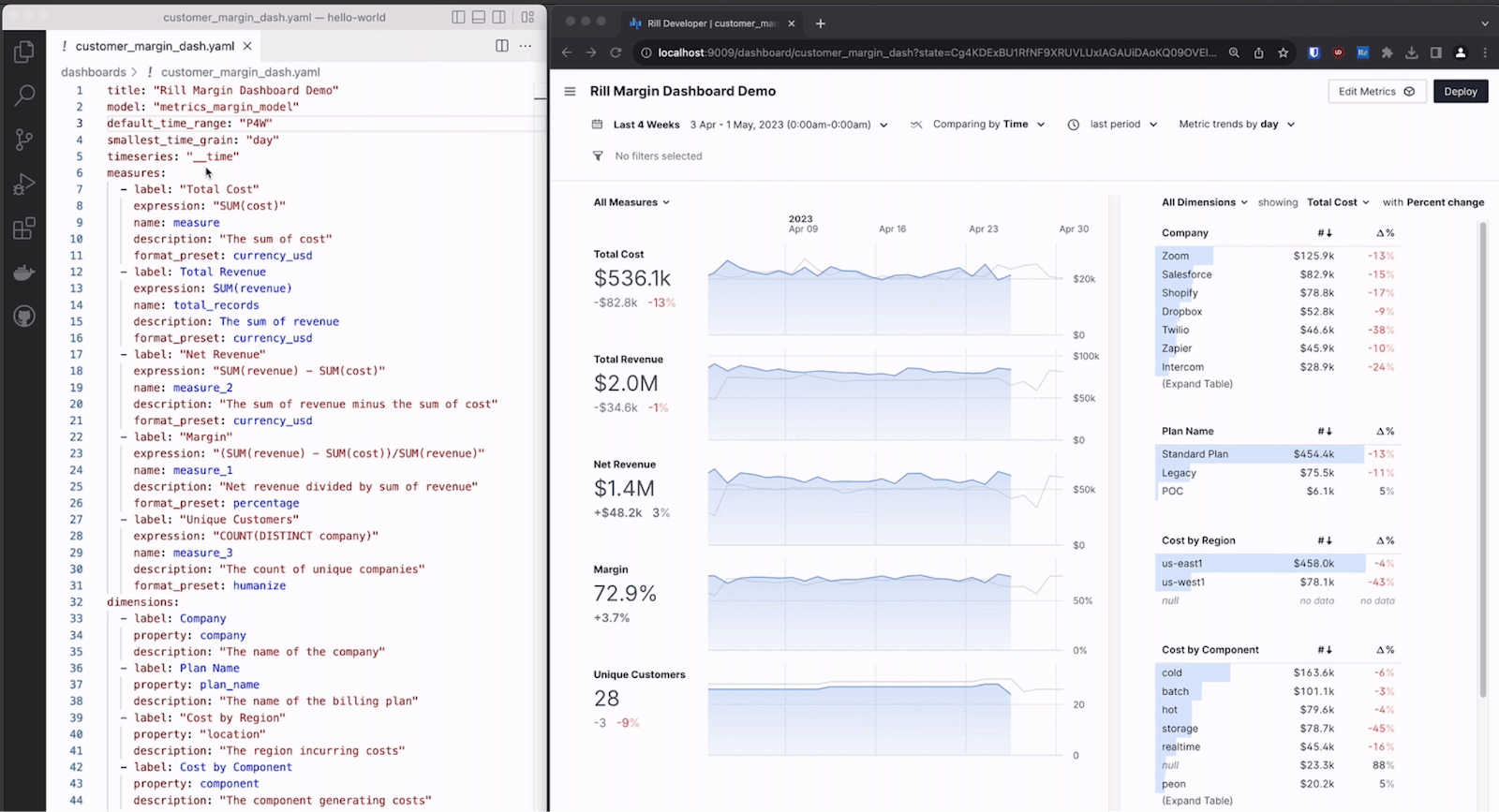
Declarative configurations in YAML or SQL are replacing point-and-click interfaces for everything from data transformation to dashboard creation.
This approach enables teams to separate business logic from technical implementation, creating systems that are more maintainable, version-controlled, and reproducible.
As data stacks continue to evolve, this code-first paradigm will increasingly become the foundation for building scalable, collaborative, and transparent data ecosystems.
Python is emerging as the standard programming interface for data tools and platforms
The third shift focuses on elevating developer experience across the data ecosystem.
At its core, this shift addresses two key preferences of data practitioners: working with tools programmatically, and doing so in Python—a language not only loved by many but also supported by a rich ecosystem of data libraries.
The widespread adoption of PyTorch, Keras, Polars, and Pandas underscores the popularity of Pythonic interfaces in the data science ecosystem.
Bauplan, a programmable data lakehouse, embraces this Pythonic approach while innovating with concepts like functions over tables, Git-like versioning for data, and serverless execution aiming to make data workflows as seamless and reproducible as modern software systems.
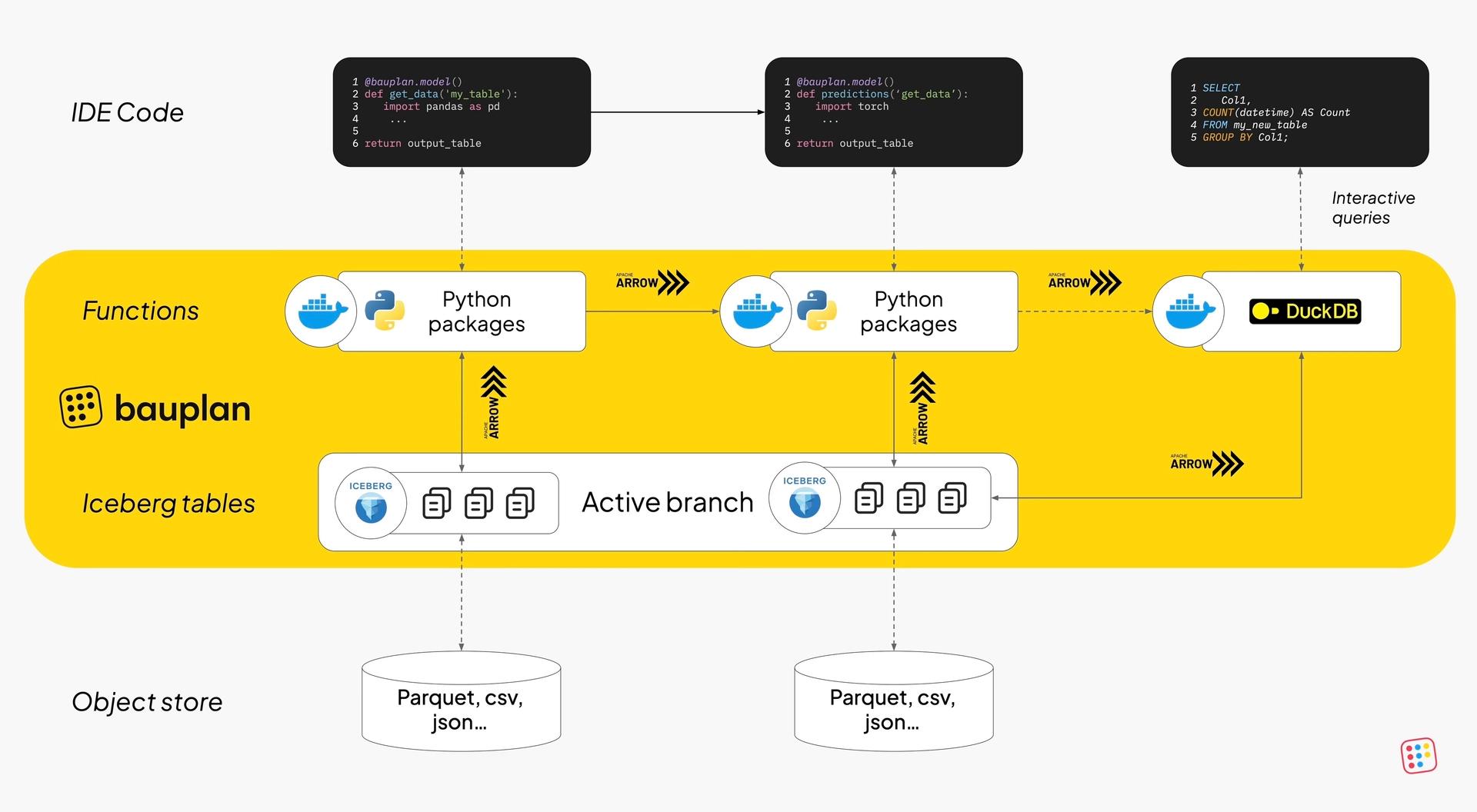
Branch-based data versioning, powered by Apache Iceberg, allows for safe testing and experimentation with transformations on production data without risking corruption.
I get that Iceberg is all the rage, but it's important to view it as an implementation detail that serves to elevate developer experience and create delightful user interactions rather than being the ultimate goal in itself.
Builders want a modern yet simple data stack
Open source projects like Iceberg, Arrow, DataFusion, DuckDB, and Substrait have created a rich landscape of plug-and-play tools that work together seamlessly regardless of vendor or origin.
And while this interoperability has created unprecedented flexibility, it also introduces a paradox of choice as teams now face an expanding universe of tools and integration patterns.
That’s why a complementary movement toward simplicity is gaining steam—what Bauplan calls “the Simple Data Stack” and what Crunchy Data calls “the Post-Modern data stack”.
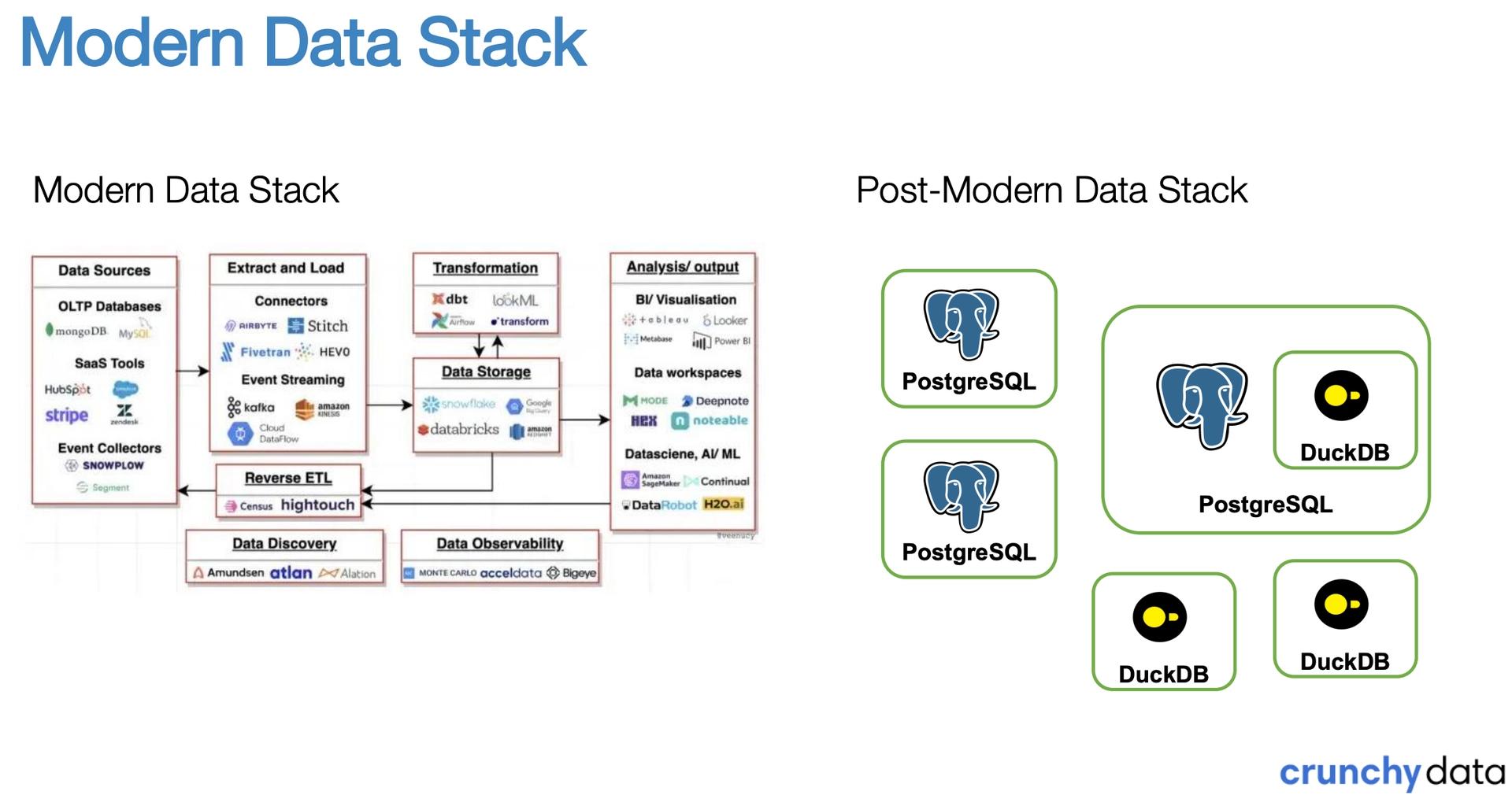
What these efforts share is a focus on seamless, integrated experiences. The companies of tomorrow—especially in a market that is characterized by the evergrowing purchasing power of developers—are those that remove complexity with the right abstractions... not add to it.
Crunchy Data's Iceberg extension for Postgres is a great example:
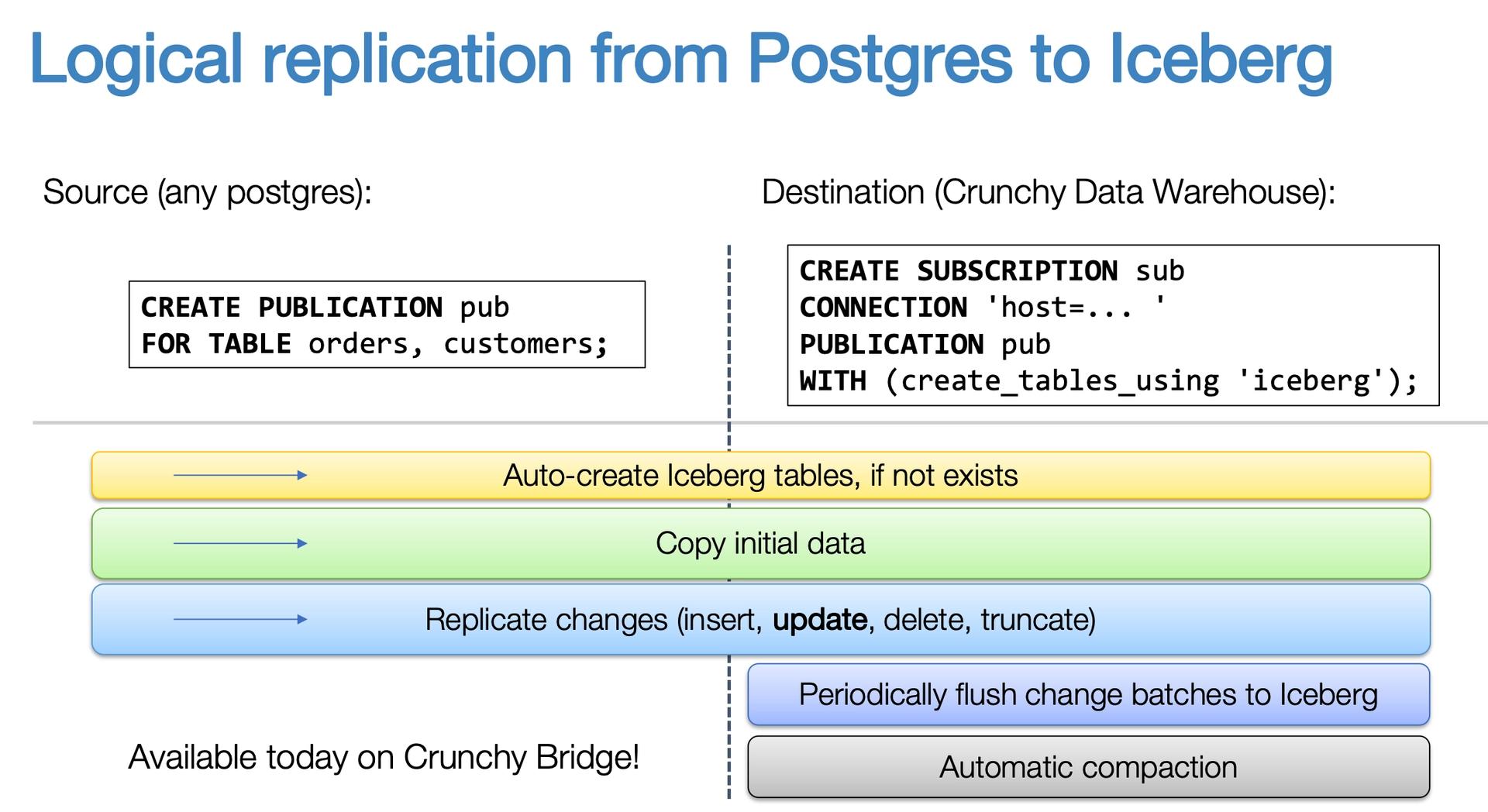
- Iceberg is a powerful format but is only valuable when accessible through user-friendly tools and interfaces.
- Crunchy Bridge enables seamless data movement from PostgreSQL to Iceberg with minimal configuration and a familiar syntax reducing what would typically be complex data pipeline setup to just two simple commands without sacrificing functionality.
- The system supports all DML operations, preserves transaction boundaries, and handles advanced features like row filters and TOAST columns.
The future belongs to flexible, unified approaches that are built for the 99% and meet developers and practitioners alike where they are, rather than forcing them to learn entirely new paradigms.
Final thoughts: Community is infrastructure
The most exciting part of Data Council wasn’t the tech.
It was the people.
Every talk, demo, and late-night side conversation reinforced a shared belief: the future of data belongs to builders who prioritize simplicity, speed, and developer empathy.
At Chalk, we’re proud to be part of that movement—and even more excited to help power the teams building what’s next.
If you’re working on real-time inference, feature platforms, or smarter ML infra—we’d love to talk.





