GROWTH DECISIONING
Build real-time
ML systems that
drive growth
Chalk helps data and ML teams power real-time decisioning systems that personalize, predict, and optimize revenue across the customer lifecycle.
TALK TO AN ENGINEER
Trusted by leading revenue intelligence and growth teams
Growth decisions in real-time
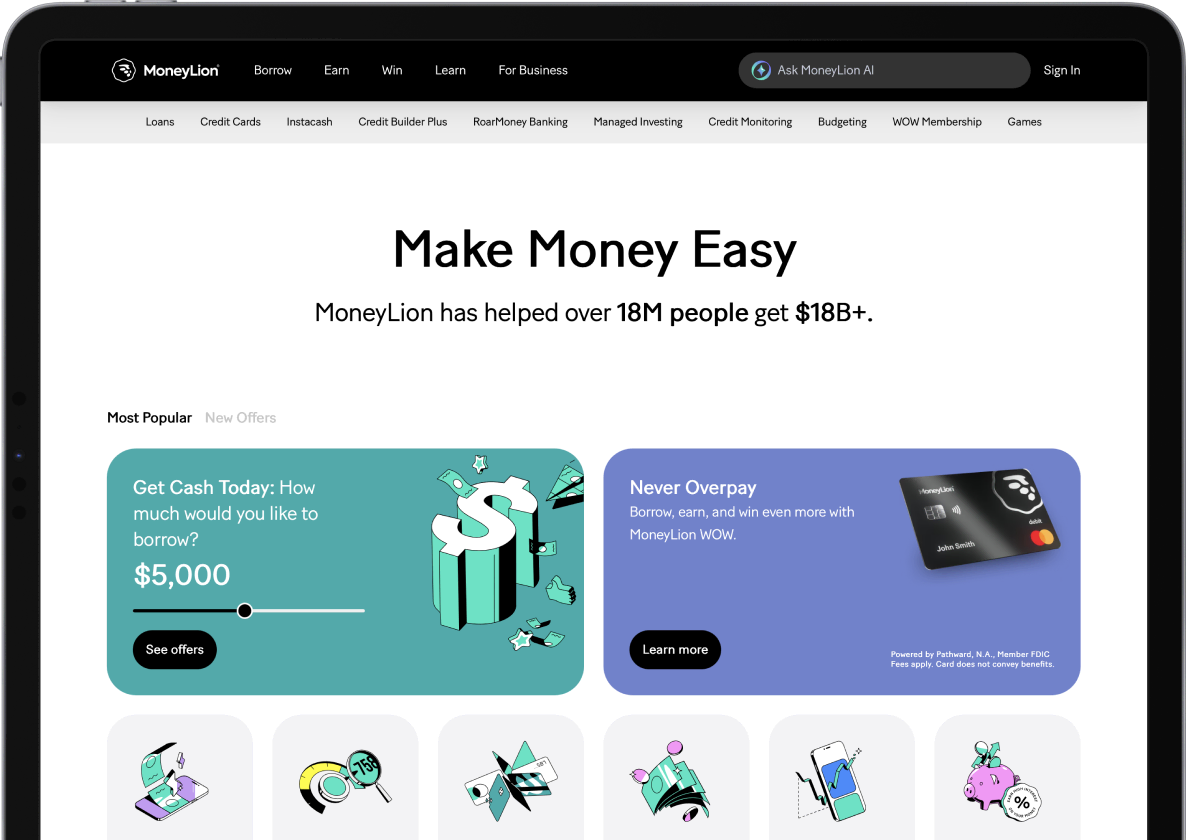
Growth decisions in real-time
MoneyLion powers dynamic product offers and retention models with Chalk, computing user and account features continuously and serving them to models in milliseconds.
Read story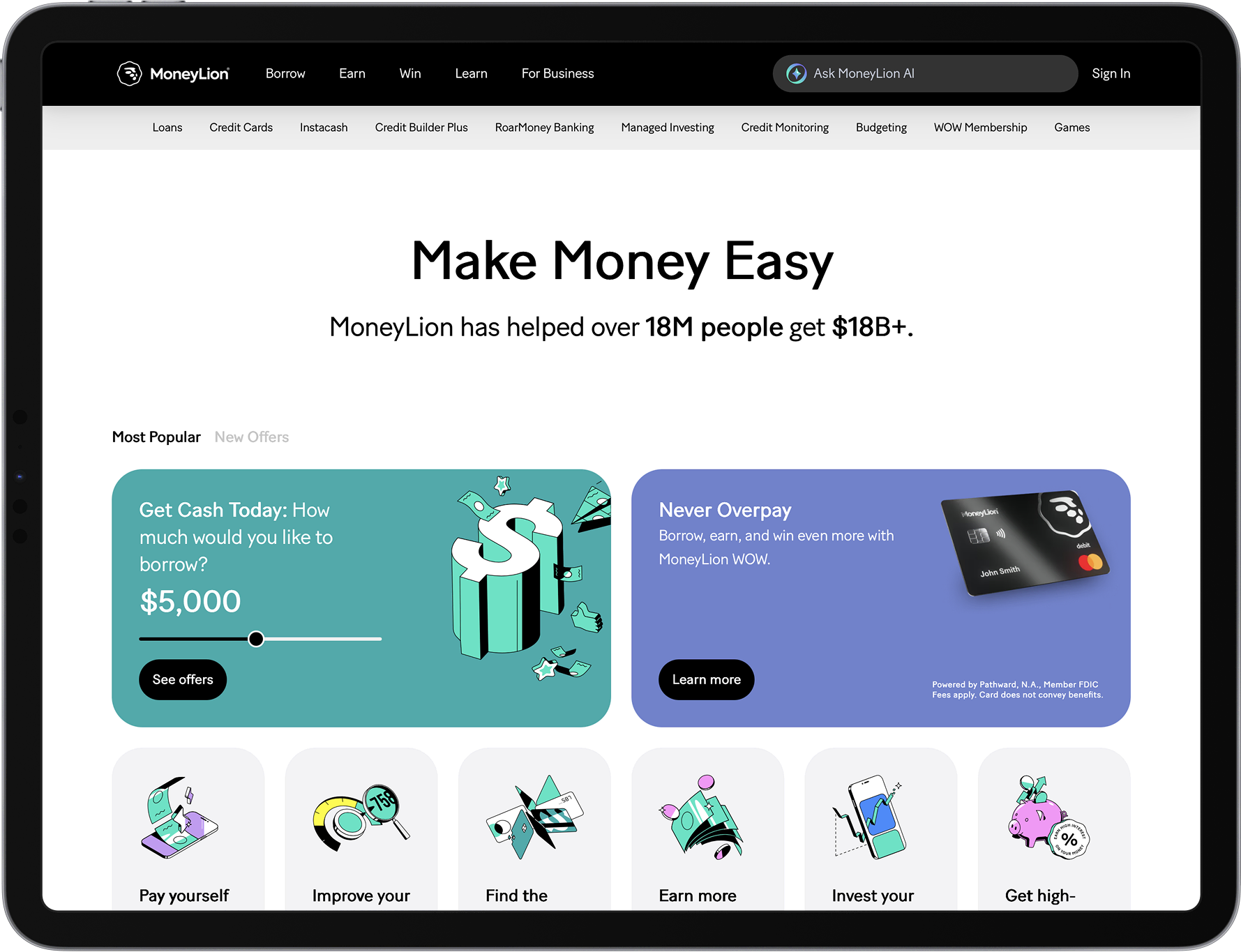
More resources
Real-Time ML for Marketing, Retention, and Pricing
Get started with Chalk today and transform your ML workflows.
TALK TO AN ENGINEER